


|
|
|
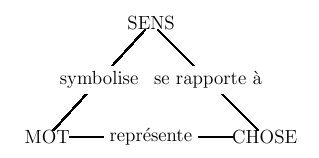
Figure 6.1 : triangle sémiotique
Explorons donc quelques uns des liens entre ces termes.
Nombre d'auteurs ont remarqué que les différentes langues humaines ne "découpent" pas le monde de la même manière. Par exemple, la traduction du mot français "bois" en allemand ne sera pas la même suivant qu'on veut désigner le matériau ("Holz") ou un sous-bois, une petite forêt ("Wald"). En danois, ce sont encore d'autres choix qui sont à l'oeuvre, comme le montre le tableau suivant :
français arbre (sous-)bois forêt allemand Baum Holz Wald danois troe skov
La façon de nommer les couleurs est un autre exemple classique de différences linguistico-culturelles. Le "spectre des couleurs" est en effet un continuum physique de longueurs d'ondes : en voir sept dans un arc-en-ciel est un choix qui n'a rien d'universel. Pour étudier les alternatives, les psychologues procèdent à des expériences où ils présentent à des locuteurs de langues différentes des petits morceaux de carton, en leur demandant de ranger ensemble ceux qui sont de la "même couleur". Le tableau suivant montre les regroupements réalisés par des représentants de cultures différentes :
français indigo bleu vert jaune orange rouge chona (Zambie) cipsw uka citema cicera cipsw uka bassa (Liberia) hui ("froides") ziza ("chaudes")
Donner le même nom de couleur à des cartons qu'on qualifie en français de "jaune" et "rouge" ne signifie pas du tout "ne voir aucune différence" entre ces cartons. Un nom de couleur doit plutôt être conçu comme une catégorie, c'est-à-dire une classe d'équivalence de perceptions acquise par éducation. De même, tout francophone a appris à désigner par la catégorie "chien" un grand nombre de perceptions très différentes... Cette capacité de catégorisation est une compétence fondamentale des êtres humains : c'est grâce à elle que le monde réel, appréhendé par des perceptions physiologiques (sons, images, gôuts, etc.) continues, peut être discrétisé en unité linguistiques distinctes.
Chaque langue "découpe" ainsi le réel suivant ses propres "catégories". Suivant certains auteurs, ce découpage a des répercutions sur le fonctionnement de la pensée. On désigne par "thèse de Sapir-Whorf" l'hypothèse suivant laquelle "les mondes où vivent des sociétés [linguistiquement] différentes sont des mondes distincts, pas simplement le même monde avec d'autres étiquettes". La langue induirait en quelque sorte une "vision du monde" ainsi qu'une manière spécifique de se situer dans l'espace et le temps, et donc finalement un mode de pensée particulier.
Cette relativité linguistique radicale est néanmoins controversée. Certaines études ont ainsi mis à jour des invariants cognitifs dans l'espèce humaine, qui se retrouvent dans certains traits de ses langues. Par exemple, si une langue ne dispose que de deux mots pour les couleurs, la distinction opérée sera toujours clair/foncé ou chaud/froid. Et si un troisième mot existe, il servira presque toujours à désigner la couleur rouge...
1.2 Sens et référence
On doit à Frege (1848-1925), mathématicien et philosophe allemand, par ailleurs aussi inventeur de la logique des prédicats du 1er ordre (que nous évoquerons dans le chapitre suivant), une distinction fondamentale entre le sens et la référence (ou la dénotation) d'une expression linguistique.
Pour définir la notion de sens, on peut s'inspirer de la façon dont nous avons procédé pour définir les catégories grammaticales : deux unités linguistiques ont le même sens si elles sont substituables l'une à l'autre dans n'importe quelle proposition en préservant la valeur de vérité de cette proposition. Un "sens" est ainsi, encore une fois, une classe d'équivalence pour une relation de substituabilité, et ce qui doit rester invariant est encore ce qui caractérise le "niveau d'analyse supérieur" (ici : la notion de "valeur de vérité"). On dit aussi que deux expressions sont "synonymes", c'est-à-dire ont le même sens, si elle sont interchangeables dans n'importe quel contexte.
Tout le mérite de Frege est de montrer que cette notion de sens ne coïncide pas avec la fonction de "désignation d'une portion du monde" par laquelle on la définit parfois. L'exemple, devenu classique, qui permet d'illustrer cette distinction, est tout ce qui sépare "l'étoile du matin" de "l'étoile du soir". Ces deux termes désignent en fait le même "astre" : la planète Vénus (qui est aussi, d'ailleurs, "l'étoile du berger"). On dit qu'ils ont la même dénotation ou qu'ils réfèrent à la même portion de la réalité. Ils ne sont pas pour autant substituables dans tous les contextes linguistiques. Par exemple, on peut très bien associer une valeur de vérité différente aux deux propositions suivantes :Deux expressions qui partagent la même référence n'ont donc pas nécessairement le même sens.
- Jean aime l'étoile du matin.
- Jean aime l'étoile du soir.
Cette distinction sens/référence a été reprise plus tard par Carnap (1891-1970), autre philosophe allemand (puis américain), sous la forme d'une distinction similaire entre ce qu'il appelle "l'intension" et "l'extension" d'un concept (ou d'une catégorie, pour reprendre notre terme précédent). Pour la comprendre, faisons un détour par les mathématiques. L'ensemble noté P des nombres pairs peut être défini de deux façons radicalement différentes :Le premier ensemble auquel P est égal est une caractérisation abstraite : c'est une définition en intension ou intensionnelle, tandis que le deuxième est une simple énumération de ses éléments : c'est une définition en extension ou extensionnelle. De même, on peut très bien définir la catégorie des "chiens" en intension, en la caractérisant comme une espèce animale ayant telles propriétés physiologiques ou génétiques, ou bien en extension, en énumérant les unes après les autres toutes ses instances ("Médor", "Milou", "Idéfix", etc.). Le première définition coïncide (à peu près) avec la notion de sens, la deuxième avec celle de référence.
- P={n∈N | ∃ p∈N, n=2p}
- P={0,2,4,6,8...}
1.3 Décomposition en primitives "sémiques"
L'analyse sémique ou componentielle (terme anglo-saxon) est une des premières tentatives systématiques de décomposition du sens d'un mot en unités de sens élémentaires. Elle est née dans le contexte de ce qu'on appelle l'analyse structurale dans les années 1960.
Dans cette théorie, l'unité minimale de signification est appelée un sème. Un sème est un trait sémantique minimal dont les seules valeurs possibles sont : positif (+), négatif (-) ou sans objet (Ø). En informatique, on dirait que c'est une variable booléenne. Un sémème est un faisceau de sèmes correspondant à une unité lexicale. L'analyse componentielle de l'ensemble des mots {jument, poulain, pouliche} pourrait ainsi ressembler au tableau suivant :
cheval mâle adulte jument + - + poulain + + + pouliche + - -
Les mots ayant un (ou des) sème(s) positifs en commun appartiennent au même champ sémantique : c'est le cas des trois mots de notre exemple, qui partagent le trait "cheval". Mais les sèmes ont aussi une fonction distinctive (ou contrastive) puisqu'ils rendent explicite ce qui fait la différence entre chaque couple de mots pris parmi ces exemples.
Les sèmes peuvent aussi servir à caractériser les différents sens possibles de mots ambigus. La figure 6.2 donne sous la forme d'un arbre la décomposition en sèmes des six significations possibles du mot "canard". Ce genre de représentation montre qu'une analyse sémique sert aussi à relier les unes aux autres les significations. Elle ne s'oppose donc pas à une conception systémique du sens, suivant laquelle les unités lexicales ne prennent sens que les unes par rapport aux autres, dans un réseau (conception que nous reprenons plus loin).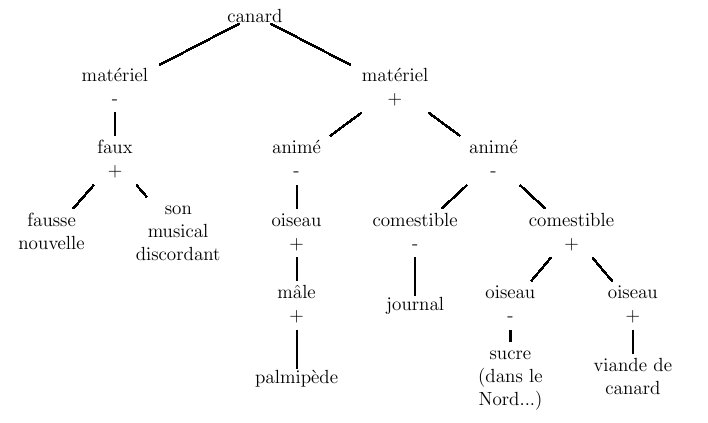
Figure 6.2 : arbre de désambiguisation à base de sèmes
Disposer d'un tel arbre peut servir à désambiguiser l'usage d'un mot dans un texte. Par exemple, dans la phrase "Jean tenait le canard dans sa main", le verbe "tenir" contraint son complément d'objet à avoir un trait "matériel", ce qui élimine toute la branche gauche de la structure. Si, dans la suite du texte, nous apprenons que "le canard s'envola", le trait "animé" doit être vérifié et l'ambiguité quant au sens du mot "canard" est levée. Mais une telle analyse nécessite quelques informations complémentaires (traits acceptés ou non en sujet ou complément de verbes) et est donc difficile à automatiser complètement.
Les critiques qu'on peut formuler à l'encontre de ce genre d'analyses sont les suivantes :Il y a eu, à notre connaissance, peu de tentatives d'utilisation à grande échelle de l'analyse sémique en tant que telle. Mais elle reste une source d'inspiration pour certains travaux contemporains. Certains formalismes syntaxiques intègrent par exemple des "traits sémantiques" à leur vocabulaire, pour contraindre la construction de phrases non seulement syntaxiquement correctes, mais aussi sémantiquement interprétables.
- même dans un domaine restreint, il y a rarement concensus entre différents auteurs sur la nature des sèmes pertinents
- personne n'a jamais prétendu exhiber un ensemble fini de sèmes à partir desquels les sens de tous les morphèmes d'une langue donnée (voire de toutes les langues possibles) pourraient être définis. Ce serait une tâche titanesque et vaine, puisque l'analyse structurale vise plutôt à comprendre les relations distinctives entre unités lexicales.
- l'analyse sémique est surtout adaptée aux mots lexicaux : quel ensemble de sèmes associer à des morphèmes grammaticaux comme "par", "de", "qui", "dont", "or", etc. ?
- quelle est exactement la nature de la composition entre sèmes appartenant à un même sémème ? Se confond-elle simplement avec un "ET" logique entre variables booléennes ? Parfois, on aurait envie de modes de compositions plus élaborés, ainsi que de règles de compatibilités entre sèmes associés à des mots liés syntaxiquement (comme dans notre exemple de canard).
1.4 Décomposition des actions selon Schank
Il existe d'autres tentatives de décomposition de la sémantique de certains mor-phèmes en primitives. Une de celles qui a été poussée le plus loin est due au spécialiste d'intelligence artificielle Roger Schank (né en 1946), et date des années 1970. Elle s'intègre dans une démarche globale de représentation des connaissances, et ce que nous en présentons ici ne rendra que très partiellement justice à l'ensemble de la proposition où elle s'inscrit (nous y reviendrons dans le chapitre suivant).
Schank estime pouvoir décrire la totalité des actions possibles en se ramenant à onze concepts de base. Cinq concernent les actions physiques :Deux autres mettent l'accent sur le résultat produit par l'action :
- PROPEL : appliquer une force à quelque chose
- MOVE : déplacer une partie du corps
- GRASP : attraper un objet
- INGEST : introduire quelque chose à l'intérieur d'un objet animé
- EXPEL : rejeter quelque chose à l'exterieur d'un objet animé
Les deux suivantes interviennent comme instrument d'autres actions :
- PTRANS : changer la position d'un objet physique
- ATRANS : changer une relation abstraite d'un objet (comme la possession)
Et les deux dernières sont des "actes mentaux" :
- SPEAK : produire un son
- ATTEND : diriger un organe sensoriel vers un stimulus
Par exemple, la vente d'un objet est une combinaison entre une action de transfert de possession de cet objet entre deux agents, et une action de transfert d'argent dans la direction opposée. Pour que ce genre de combinaisons soit possible, il faut ajouter un certains nombres de descripteurs que nous n'aborderons que dans le chapitre suivant, parce qu'ils relèvent plutôt de la sémantique propositionnelle : c'est le cas notamment des rôles sémantiques, qui décrivent des fonctions comme "acteur", "objet", "bénéficiaire", etc.
- MTRANS : transfert d'information d'un indivisu à un autre, ou entre deux éléments de la mémoire d'un même individu
- MBUILD : création de nouvelles pensées
Cette proposition a le mérite de se présenter comme complète, et d'être intégrée dans un système de représentation des connaissances de plus haut niveau. Son originalité est de s'appliquer plutôt aux verbes qu'aux noms, ce qui est assez rare pour être souligné. Elle a été mise en oeuvre par Schank, et a été parfois reprise dans certains systèmes ultérieurs. Nous la retrouverons dans le chapitre suivant, intégrée à des formalismes de représentation du sens de propositions complètes (voir le chapitre 7, section 2.4).
1.5 Analyses par prototypes et proximités
Pour éviter la "circularité du sens" dans le domaine du lexique, la principale alternative à la décomposition en primitives repose sur la prise en compte des liens qu'entretiennent les morphèmes entre eux. Saussure, déjà, considérait que le langage constituait un système et que la sémantique d'une unité se mesurait surtout à l'aune de ses différences et similitudes avec les autres unités (suivant un axe "paradigmatique").
Cette hypothèse a été en partie confirmée par des études psycholinguistiques menée par Eleanor Rosch sur l'organisation de la mémoire humaine menées dans les années 70, visant à comprendre comment s'opérait la catégorisation. La conception classique, datant d'Aristote, qu'on avait à cette époque d'une catégorie était celle d'une conjonction nécessaire et suffisante de traits (qu'on peut assimiler à des sèmes) : on supposait, par exemple, que l'appartenance d'un individu à la catégorie " oiseau" pouvait se décider en vérifiant si celui-ci satisfaisait chacun des critères de l'ensemble { vole, a-des-plumes, a-des-ailes, a-un-bec, est-ovipare, etc.}. Pourtant, tous les individus catégorisés en "oiseau" ne satisfont pas chacun de ces traits : l'autruche, le pingouin ou le poussin ne volent pas, le kiwi et le pingouin n'ont pas vraiment de plumes, etc.
En fait, il semble que la catégorisation humaine fonctionne plutôt par proximité à un prototype. A chaque catégorie, pourrait ainsi être associé un représentant privilégié appelé prototype, qui exprime l'essence des propriétés des membres de cette catégorie : le "moineau" ou le "rouge-gorge" pourraient jouer ce rôle pour la catégorie "oiseau". L'appartenance d'un individu à une catégorie s'évalue alors par sa proximité avec le prototype : c'est une question de degré plus que de frontière claire. Ce fonctionnement a pu être validé en mesurant les temps de réponse à des tests de catégorisation : plus on présente à un sujet humain une instance qui "ressemble" au prototype, plus son appartenance à la catégorie est jugée rapidement.
Cette nouvelle conception de la sémantique en terme de "proximités" est souvent rapprochée de la "ressemblance de famille" proposée bien avant par le philosophe Wittgenstein (1889-1951) pour analyser "les processus que nous nommons "jeux"" : jeux de plateau, de cartes ou de balles, jeux solitaires ou collectifs, jeux compétitifs -ou pas-, divertissants -ou pas-, où interviennent -ou pas- la chance, l'adresse... L'ensemble des jeux n'est pas caractérisable par un ensemble de traits fixe : à la place, "nous voyons un réseau complexe de similitudes qui s'entrecroisent et s'enveloppent les unes les autres". Certains auteurs ont proposé de représenter ce "réseau" par des cercles qui ont certaines intersections communes, à la manière de la figure 6.3.
Il faut imaginer que chaque instance de "jeu" figure dans un des cercles. Cette figure très simplificatrice (on peut envisager des recoupements plus complexes) illustre surtout que chaque cercle a des traits commun avec un ou plusieurs autres, mais aussi qu'il existe des cercles (et donc des instances de jeux) qui ne partagent aucun trait. Ils sont identifiés comme appartenant à la catégorie des jeux en vertu de proximités successives, et non parce qu'ils vérifient une propriété particulière.
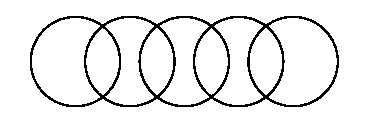
Figure 6.3 : représentation graphique de la "ressemblance de famille"
1.6 Organisations hiérarchiques
Même si, bien sûr, ce vocabulaire n'était pas présent dans ses textes, chacun des types de jeux évoqués par Wittgenstein constitue une "sous-catégorie" spécifique de la catégorie "jeu" et pourrait même avoir son prototype propre. De même, la catégorie "oiseau" est un cas particulier de la catégorie "animal", elle-même cas particulier de la catégorie "être vivant", etc. L'ensemble des catégories peut donc être organisé de manière hiérarchique par la relation "est un cas particulier de", comme dans la figure 6.4 où cette relation est représentée par une flèche.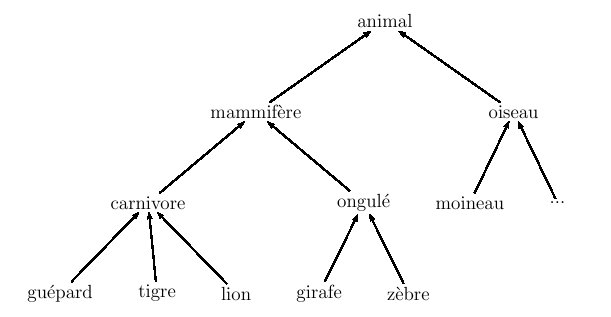
Figure 6.4 : organisation hiérarchique d'une ensemble de catégories
Ce genre de modélisation est devenue la base des langages de programmation "orientés objets". Ils s'accompagnent dans ce cadre de mécanismes d'héritage : sauf exceptions explicitement déclarées, les catégories "inférieures" héritent des propriétés et fonctions de leur(s) ancêtre(s). Par exemple, si la propriété "voler" est associée à la catégorie "oiseau", elle sera automatiquement associée aussi à toutes les sous-catégories d'oiseaux.
La mémoire humaine est probablement aussi organisée de façon similaire. Mais tous les éléments figurant dans une structure de ce genre ne sont pas pour autant équivalents d'un point de vue psychologique : des expériences ont montré que, quand on demande à quelqu'un de décrire une situation ou une image, il a tendance à utiliser les catégories se situant à un certain niveau dit "de base" dans cette hiérarchie : il utilisera le mot "oiseau" ou "lion" plutôt qu'"animal". Ces mots ne se situent d'ailleurs pas toujours au même niveau global dans notre arbre de la figure 6.4 : le "niveau de base" psycholinguistique ne correspond pas nécessairement à un niveau précis des taxonomies scientifiques ; il peut être différent pour chaque "branche" de l'arbre.
Une organisation hiérarchique implique l'existence d'une relation d'ordre. Ainsi, malgré les apparences, l'arbre de la figure 6.2 permettant de distinguer les différents sens de "canard" n'est pas vraiment hiérarchique. En effet, l'ordre dans lequel les sèmes y sont évalués est relativement arbitraire, et on peut même retrouver le même test à des niveaux distincts dans différentes branches (c'est le cas du trait "oiseau" dans notre exemple).
Les arbres du type de la figure 6.4 ont une traduction contemporaine dans la notion d'ontologie. Ce terme, hérité de la philosophie, signifie littéralement "science de ce qui est". L'informatique l'a réinvesti récemment pour le "Web sémantique", projet de mise en commun de connaissances générales et de données factuelles via Internet. Dans ce contexte, une ontologie est une hiérarchie de concepts censés être indépendants d'une langue donnée et founissant un vocabulaire général (comme le fait que les oiseaux sont des animaux et volent) pour décrire des connaissances plus spécifiques (concernant par exemple des instances particulières d'oiseaux).
Il existe une autre branche de la linguistique dans laquelle la structuration hiérarchique est bien ancrée : c'est la terminologie, l'étude des termes (cf. chapitre 5, section 1.2) pouvant servir de mots clés dans l'indexation d'un texte. Pour aider les documentalistes à naviguer dans un ensemble de mots clés, les terminologues les organisent dans un thesaurus comme celui de la figure 6.5 (fondé sur un petit échantillon de genres cinématographiques).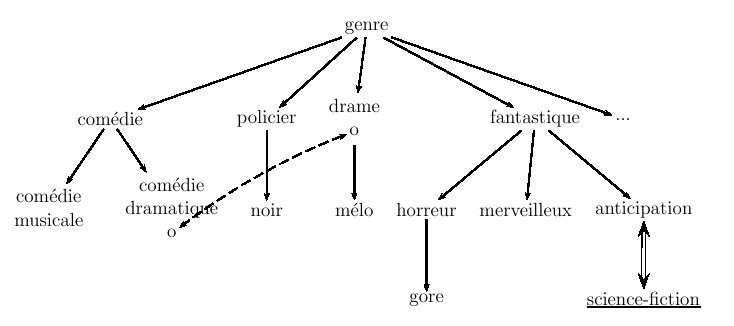
Figure 6.5 : petit thesaurus de genres cinématographiques
Les principales propriétés d'un thesaurus comme celui-ci sont les suivantes :Les thesauri sont des outils linguistiques : ils permettent d'élargir un critère de recherche d'information sur la base de relations sémantiques contrôlées. Il n'ont pas pour ambition de modéliser le sens global des termes qui y figurent, mais seulement d'expliciter quelques-une de leurs relations.
- il ne contient que des termes, sous la forme de noms communs ou de groupes nominaux, en général en forme lemmatisée ;
- les termes figurant dans un thesaurus sont censés être représentatifs d'un certain domaine ;
- parmi ces termes, certains sont descripteurs (ils peuvent servir à indexer un texte), tandis que d'autres sont non descripteurs (ils ne doivent pas être utilisés lors d'une l'indexation). Ces derniers doivent être reliés à des termes descripteurs du thesaurus, qui leur seront substitués si quelqu'un les emploie lors d'une requête. Dans notre exemple, le terme "science fiction" est souligné pour signaler qu'il n'est pas descripteur.
- les termes sont liés entre eux par des relations. On considère classiquement trois types de relations possibles :
- la relation "générique/spécifique" est une relation d'ordre : elle fournit la structure globale du thesaurus mais ne le contraint pas pour autant à être représentable sous la forme d'un unique arbre : il n'y a pas nécessairement unicité du terme le plus général. Elle est représentée dans notre figure par une flèche.
- la relation de "synonymie" (aussi notée "employée pour") est symétrique et relie deux termes pouvant être échangés l'un avec l'autre : de ce fait, elle est souvent utilisée pour relier un terme descripteur et un terme non descripteur, comme c'est le cas dans la figure entre "anticipation" et "science fiction".
- la relation "terme associée" associe deux termes du même "champ sémantique" sans être pour autant synonymes : elle sert à étendre une requête à des termes sémantiquement proches : la flèche en pointillées entre "drame" et "comédie dramtique" en est une instance dans notre thesaurus.
D'autres relations sémantiques peuvent bien sûr être définies entre unités lexicales, et contribuer à enrichir un réseau de sens plus complexe qu'un arbre.
1.7 Critiques générales et alternatives
Nous avons dans ce chapitre, plus que dans les précédents, cité les noms des auteurs des théories et concepts introduits. C'était, en partie, parce que le corpus des travaux sur la sémantique n'est pas aussi consensuel et "unifié" que certains des autres domaines évoqués. Peut-être n'a-t-il pas encore atteint le même niveau de maturité scientifique.
Aucune des théories et propositions évoquées jusque là ne sont en effet exemptes de critiques. Elle ne traitent, pour la plupart, que de la caractérisation du sens d'une toute petite partie d'un lexique : en général les noms communs, plus rarement les verbes.
Que dire, par exemple, du sens des adjectifs ? Ces derniers servent traditionnellement à exprimer des qualités attribuées aux noms auxquels ils s'adjoignent. Mais la caractérisation du sens d'un adjectif est un problème difficile, car il dépend souvent de son environnement syntaxique. Certains adjectifs, en effet, décrivent une propriété relativement "autonome" : les couleurs d'une "maison bleue" et d'une "orange bleue" sont sans doute comparables. Mais d'autres adjectifs sont indissociables du nom qu'ils qualifient : un "grand écrivain" est "grand en tant qu'écrivain" et pas nécessairement "grand" pour autant. D'ailleurs, même le sens usuel de "grand" est relatif à l'échelle du nom considéré : une "grande souris" et une "grande girafe" n'ont certainement pas la même taille. Sans compter que certains adjectifs changent de sens en français suivant qu'ils sont anté ou post-posés (mis avant ou après le nom) : un "homme pauvre" n'est pas forcément un "pauvre homme", etc.
Autant les noms communs et les entités nommées jouent un rôle crucial pour savoir "de quoi" parle un texte, autant les adjectifs et les verbes sont fondamentaux pour connaître "comment" il en parle. Les systèmes qui essaient de classer les textes porteurs d'opinion (par exemple les critiques littéraires ou cinématographiques, les argumentations militantes, les compte-rendus d'utilisation d'un produit, etc.) en plus ou moins "favorables" se focalisent en général sur les adjectifs et les verbes qu'il contiennent.
Le cas des adverbes est encore moins souvent abordé. Ces derniers jouent en effet souvent le rôle de modifieurs : leur fonction est de renforcer ou d'amoindrir le sens des mots (en général adjectifs ou verbes) avec lesquels ils apparaissent, comme dans "courir vite" ou "très cher". Leur sémantique est donc difficile à décrire en elle-même. Et, enfin, le sens des morphèmes grammaticaux ne peut être envisagé que si on dispose d'une théorie du sens global d'une proposition, dont ils constituent des briques indispensables. Nous y reviendrons donc dans le chapitre suivant.
Citons pour finir une approche récente et assez prometteuse, qui tente de remédier à plusieurs de ces critiques : la théorie du lexique génératif, introduite par le linguiste américain Pustejovsky dans un livre de 1998. Son ambition est d'expliquer la sémantique de toutes les unités lexicales en contexte à partir d'un "ensemble noyaux" et de mécanismes génératifs et dérivationnels. Pour cela, Pustejovsky propose d'associer à chaque unité lexicale quatre niveaux distincts de représentation :On le voit, cette théorie est déjà très articulée et complexe, et il n'est pas question de la détailler plus avant ici. Elle cherche à analyser le sens d'un mot en le décomposant en différentes facettes, qui contraignent la façon dont il se combine avec d'autres dans une phrase. Elle est l'objet de nombreux travaux et discussions à l'heure actuelle.
- une structure argumentale qui spécifie le nombre et le type de ses arguments (ex : sujet et complément direct d'un verbe transitif)
- une structure événementielle, par laquelle on distingue les activités, les états et les transitions
- une structure de qualia, qui se décompose elle-même en quatre rôles :
- le rôle constitutif décrit la relation entre l'objet référencé par le mot et ses composantes : par exemple, pour un "livre", ses pages, sa couverture...
- le rôle formel est ce qui distingue l'objet d'un domaine plus large : celui d'un livre est de contenir de l'information
- le rôle télic est la fonction pour laquelle l'objet a été conçu : celle d'un livre est d'être lu
- le rôle agentif explicite les facteurs impliqués dans sa création : l'auteur du livre.
- une structure d'héritage lexical
Les approches citées jusqu'à présent relèvent surtout des deux premières "familles" identifiées en introduction de ce chapitre : celles qui privilégient le découpage en primitives (ou en "facettes" !) et celles qui préfèrent une conception du sens en réseau. La troisième famille, où l'on cherche à définir un "monde de sens" propre, concerne en fait plutôt la sémantique propositionnelle et sera donc surtout représentée par les exemples du chapitre qui suit.
2 Modélisation informatique
Nous l'avons déjà annoncé : cette partie sera limitée parce que nous avons préféré mettre sur le même plan, dans la partie précédente, les "descriptions linguistiques" et les "modèles informatiques". La frontière entre les disciplines est parfois difficile à tracer en la matière. Par exemple, l'analyse sémique a été élaborée dans un contexte linguistique, mais elle est implémentable assez facilement (et cela a parfois été tenté). Pour continuer à brouiller les pistes, nous nous contenterons ici de retranscrire un argumentaire philosphique célèbre qui nie la possibilité même pour un ordinateur d'avoir accès au "sens" véhiculée par le langage.
2.1 Critique épistémologique
En 1980, le philosophe américain John Searle a fait paraître un article où il imaginait ce qui est désormais connu comme l'expérience de pensée de la "chambre chinoise".
Dans cette expérience, il demande au lecteur de se mettre dans la peau d'un expérimentateur enfermé dans une pièce. La pièce communique avec un interlocuteur extérieur grâce à un dispositif matériel quelconque (papier passé sous la porte ou boîte aux lettres électronique). Les informations qui s'échangent par ce canal se font uniquement en chinois. Bien sûr, Searle s'adresse à des lecteurs qui ne sont pas censés parler le chinois : la langue elle-même a peu d'importance mais l'important est qu'elle n'est pas comprise par la personne se trouvant dans la pièce.
L'expérimentateur dispose d'un stock suffisant de caractères chinois (ou il sait les produire avec un ordinateur), et d'un manuel rédigé dans sa langue maternelle. Quand un texte en chinois lui parvient, il consulte le manuel. Celui-ci est rédigé sous forme de règles qui lui expliquent, en fonction des caractères figurant dans le message reçu, quels caractères il doit à son tour choisir pour répondre. L'expérimentateur se contente d'exécuter les ordres du manuel. Si celui-ci est bien fait, on pourrait avoir l'impression qu'une vraie conversation en chinois a eu lieu entre la pièce et l'interlocuteur externe.
La "chambre chinoise" reproduit en fait le comportement d'un ordinateur programmé pour réussir le "test de Turing" (cf. chapitre 2, section 5). Le manuel joue le rôle du programme, l'expérimentateur celui de l'unité centrale. Même si le test est "réussi", la personne enfermée dans la pièce n'aura à aucun moment "compris" quoi que ce soit à la nature de la discussion, et encore moins à la langue chinoise... Le coeur de l'argument de Searle, c'est que la compréhension ne peut se réduire à la manipulation syntaxique (au sens de "régie par des règles formelles") de symboles. Or, c'est la seule chose dont sont capables les ordinateurs.
Cet article a provoqué, dans les années qui ont suivi sa parution, un débat intense (pas encore totalement clos), où les échanges d'arguments et de contre-contre-arguments ont été particulièrement riches. Parmi les "reponses" les plus souvent mises en avant, on retiendra les suivantes :L'engouement qu'a suscité l'article de Searle témoigne à tout le moins qu'il a pointé un problème important pour la communauté des chercheurs en "intelligence artificielle". Depuis, les informaticiens ne prétendent en général plus reproduire l'intelligence humaine dans leurs programmes, mais au mieux simuler ses effets par d'autres moyens. Ils adoptent la plupart du temps une démarche très pragmatique, consistant simplement à exploiter au mieux les capacités de calcul de leurs machines.
- l'expérimentateur, à lui tout seul, ne comprend pas le chinois, mais cette compétence émerge peut-être de l'ensemble du dispositif, de même qu'aucun neurone ne comprend non plus le langage, qui est une compétence plus globale du cerveau.
- le sens émerge du lien entre les mots et les choses auxquels ils réfèrent : ce qui manque aux ordinateurs, ce sont des organes sensoriels pour percevoir leur environnement, les catégoriser, et les relier à des unités lexicales. On peut ainsi espérer que des robots dotés de capteurs, capables de catégoriser les données qui leur en parviennent et de leur associer un symbole linguistique auraient, eux, une vraie "compréhension" de ces symboles.
2.2 Sites Web
Les sites Web référencés ci-dessous illustrent principalement la représentation du sens d'unités lexicales sous forme de réseaux ou d'arbres. Dans le chapitre suivant, seront présentés d'autres projets qui visent à expliciter des connaissances plus générales, et qui intègrent souvent une décomposition du sens en unités plus élémentaires.
Le plus célèbre projet lexicologique mené jusqu'à une réalisation informatique effective est le réseau "Wordnet", né de travaux psycholinguistiques sur le fonctionnement de la mémoire humaine. Wordnet est un dictionnaire hypertexte -et bien plus que cela- : il contient des mots de toutes catégories (y compris des entitées nommées) et est structuré par un grand nombre de relations. A partir d'un mot, on peut avoir accès à son ou ses hyperonymes (mots "plus généraux que"), hyponymes (mots "moins généraux que"), antonymes ("mots de sens opposé à"), etc.
Il en existe une version pour les langues européenne, nommée "Eurowordnet", incluant le français, mais elle est payante. Eurowodnet a, semble-t-il, été fait plus en traduisant Wordnet qu'en reconsidérant les liens sémantiques propres à chaque langue, et ses utilisateurs n'en sont pas toujours très satisfaits.
Quelques ontologies (anglaises) plus ou moins générales et ambitieuses : Quelques thesauri (français) dans lesquels on peut naviguer en ligne :Autres représentations de relations sémantiques en réseaux (pour le français) :
- grds.ebsi.umontreal.ca/r/thesaurus-activite-gouvernementale/site-web/categories.htm
- www.bdsp.tm.fr/TSP3/Default.asp
- europa.eu/eurovoc/ (multilingue)
- www.enekia.com/thesaurus.html
- www.memodata.com/2004/fr/dictionnaire_des_synonymes/TGLinkBrowser.shtml