5.1 Natural Language, Syntax and Context-Free Grammar
Natural language has an underlying structure usually referred to under the heading of Syntax. The fundamental idea of syntax is that words group together to form so-called constituents i.e. groups of words or phrases which behave as a single unit. These constituents can combine together to form bigger constituents and eventually sentences. So for instance, John, the man, the man with a hat and almost every man are constituents (called Noun Phrases or NP for short) because they all can appear in the same syntactic context (they can all function as the subject or the object of a verb for instance). Moreover, the NP constituent the man with a hat can combine with the VP (Verb Phrase) constituent run to form a S (sentence) constituent.
A commonly used mathematical system for modelling constituent structure in Natural Language is Context-Free Grammar (CFG) which was first defined for Natural Language in (Chomsky 1957) and was independently discovered for the description of the Algol programming language by Backus (backus 1959) and Naur (Naur et al. 1960).
Context-Free grammars belong to the realm of formal language theory (cf. Hopcroft and Ullman 1974 for a detailed overview) where a language (formal or natural) is viewed as a set of sentences; a sentence as a string of one or more words from the vocabulary of the language and a grammar as a finite, formal specification of the (possibly infinite) set of sentences composing the language under study. Specifically, a CFG (also sometimes called Phrase-Structure Grammar) consists of four components:
T, the terminal vocabulary: the words of the language being defined
N, the non-terminal vocabulary: a set of symbols disjoint from T
P, a set of productions of the form
a -> b, where a is a non-terminal and b is a sequence of one or more symbols from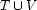
S, the start symbol, a member from N
A language is then defined via the concept of derivation and the basic operation is that of rewriting one sequence of symbols into another. If a -> b is a production, we can rewrite any sequence of symbols which contains the symbol a, replacing a by b. We denote this rewrite operation by the symbol ==> and read u a v ==> u b v as: u b v directly derives from u a v or conversely, u a v directly produces/generates u b v. For instance, given the grammar G1
S -> NP VP
NP -> PN
VP -> Vi
PN -> John
Vi -> runsthe following rewrite steps are possible:
(D1) S ==> NP VP ==> PN VP ==> PN Vi ==> John Vi ==> John runswhich can be captured in a tree representation called a parse tree e.g.,:
ADD TREE
So John runs is a sentence of the language defined by G1. More generally, the language defined by a CFG is the set of terminal strings (sequences composed entirely of terminal symbols) which can be derived by a sequence of rewrite steps from the start symbol S.
5.1.1 Parsing
A CFG only defines a language. It does not say how to determine whether a given string belongs to the language it defines. To do this, a parser can be used whose task is to map a string of words to its parse tree.
When proceeding through the search space created by the set of parse trees generated by a CFG, a parser can work either top-down or bottom-up. A top-down parser builds the parse tree from the top, working from the start symbol towards the string. The exemple derivation D1 given above illustrates a top-down parsing process: starting from the symbol S, productions are applied to rewrite a symbol in the generated string until the input string is derived. By contrast, a bottom-up parser starts from the input string and applies productions in reverse until the start symbol is reached. So for instance, assuming a depth-first traversal of the search space and a left-to-right processing of the input string, a bottom up derivation of John runs given the grammar G1 would be:
John runs ==> PN runs ==> PN V ==> NP V ==> NP VP==> SThe parse tree of course remains the same. In the remainder of this chapter, we show how to implement a bottom-up CF-parser in Oz.