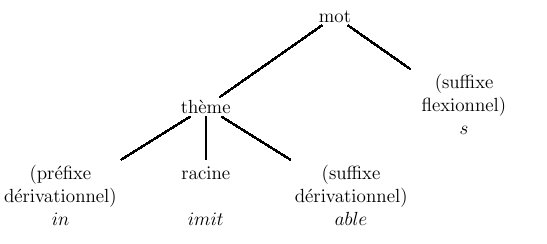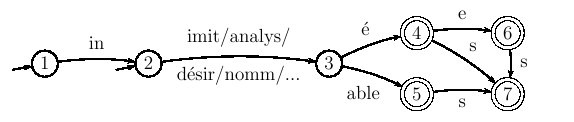
Figure 4.3 : un automate morphologique
Dans cette représentation, les états sont représentés par des
"ronds" numérotés.
Q est donc ici l'ensemble des nombres de 1 à
7 (l'ordre de numérotation est totalement arbitraire). Les états
initiaux sont ceux sur lesquels arrive un flèche "qui ne vient de
nulle part" : c'est le cas dans notre exemple des états 1 et
2. Les états finaux, eux, sont visualisés par un "double rond": ce
sont les états 4, 5, 6 et 7. Rien n'empêcherait en théorie
qu'un état puisse être à la fois initial et final, mais il n'y en a
pas dans notre exemple.
Chaque flèche dont le point de départ et le point d'arrivée sont des
états et qui porte une étiquette prise dans le vocabulaire
V
correspond à une
transition. Par exemple, la flèche entre les
états 3 et 5 est la traduction du fait que la fonction de
transition
f prend pour valeur 5 quand elle a pour données 3 et
able, autrement dit :
f(3,
able)=5. Entre les états 2 et 3, il
faut considérer qu'il y a en réalité 4 flèches différentes, chacune
portant un morphème distinct. C'est uniquement pour des questions de
lisibilité qu'on n'en a représenté qu'une seule (les "/" séparant
les morphèmes signifient qu'il faut en choisir un parmi ceux
énumérés). Rien n'empêcherait en théorie qu'une flèche ait pour point
de départ et point d'arrivée le même état (elle serait représentée
alors par une "boucle" sur cet état) , mais il n'y en a pas dans
notre exemple.
Un automate permet de caractériser un ensemble de
chemins. Un
chemin dans un automate commence nécessairement à partir d'un état
initial, suit des transitions et aboutit à un état final. Le
langage de l'automate est l'ensemble de suites (ou
concaténations) d'éléments du voacabulaire
V qui correspondent à un
tel chemin. Le langage de notre automate contient ainsi tous les mots
évoqués au début de cette section, et toutes leurs variantes
morphologiques. C'est un
langage fini parce qu'on peut énumérer
tous ses éléments dans une liste finie. Il existe d'autres automates
reconnaissant le même langage. Par exemple, un automate avec seulement
un état initial et un état final, et autant de transitions que de mots
distincts conviendrait tout aussi bien en termes de langage. Mais
celui de la figure
4.3 met en évidence des
régularités de construction que n'auraient pas l'autre (équivalent à
une simple liste). Nous l'avons de plus construit pour que chaque état
final identifie une variante flexionnelle distincte :
-
l'état 4 identifie le masculin singulier ;
- l'état 6 identifie le féminin singulier ;
- l'état 5 identifie le masculin ou le féminin singulier ;
- l'état 7 identifie le pluriel (on aurait pu distinguer
"masculin pluriel" et "féminin pluriel" pour les formes en
"é(e)s" mais pas pour les formes en "able", d'où cette
indifférenciation).
Les automates sont particulièrement bien adaptés à la modélisation des
phénomènes d'affixation. On peut ainsi facilement construire des
automates qui explicitent les règles de conjugaison des verbes, mais
il faut alors autant d'automates différents qu'il y a de familles de
conjugaisons différentes possibles. Dans ce cas, on peut aussi faire
en sorte que les états finaux distincts identifient les différentes
personnes (1ère, 2ème ou 3ème) et le nombre (singulier ou pluriel) de
la conjugaison. Le verbe "troufigner", imaginé dans les sections
précédentes, aurait ainsi toutes les chances de se conjuguer comme
"aligner" et tous les autres verbes réguliers du 1er groupe. Le fait
de déjà disposer d'un automate pour caractériser cette conjugaison
évite d'en inventer une nouvelle, et économise donc son stockage en
mémoire.
Un des principaux intérêts des automates (comme des grammaires
formelles dont nous verrons plus loin qu'ils ne sont qu'un cas
particulier) est qu'ils peuvent fonctionner
aussi bien en
analyse qu'en synthèse. En analyse, on dit que l'automate
"reconnaît" un mot s'il existe un chemin correct étiqueté par ce
mot. En synthèse, on dit qu'on "génère" ou "engendre" un mot en le
produisant au fil des transitions de l'automate.
| 2.3 |
Expressions régulières |
|
Les automates finis ont été très étudiés par Chomsky et les pionniers
de l'informatique théorique, à partir des années 60, et un très grand
nombre de leurs propriétés formelles ont alors été explicitées. Nous
n'évoquerons ici que quelques-unes d'entre elles, sans rentrer dans
les détails techniques et sans fournir aucune démonstration.
Les automates finis reconnaissent (ou engendrent, suivant le point de
vue adopté) une
classe de langages particulière appelée
langages réguliers ou
langages rationnels. Un langage
est régulier (ou rationnel) s'il existe un automate qui reconnaît
exactement ce langage. On peut aussi caractériser cette famille de
langages par d'autres moyens. Nous verrons plus loin une
caractérisation en termes de grammaires formelles. Ici, nous
présentons la caractérisation par les
expressions régulières.
Une
expression régulière est une suite de symboles prise parmi :
-
un vocabulaire fini V
- le symbole ε qui représente la "chaîne vide"
- les symboles : "|" et ".", ainsi que les parenthèses "(" et ")"
- les symboles "+" et "*" utilisés en exposants
Elle doit être de plus bâtie en respectant les règles de construction
suivantes :
-
tout élément de V∪{ε} est une expression régulière ;
- si U est une expression régulière, alors (U) est aussi une
expression régulière : les parenthèses sont utilisées comme en
mathématiques, pour délimiter des sous-parties d'expressions
régulières ;
- si U et T sont toutes les deux des expressions régulières,
alors U|T et U.T (souvent réduite à UT) sont des expressions
régulières : U|T=U∪ T={w|w∈ U ou w∈ T} représente le choix entre
un élément de U et un élément de T, tandis que UT={ut|u∈ U
et t∈ T} représente l'ensemble des concaténations d'un élément
de U et d'un élément de T ;
- si U est une expression régulière, alors U+ et U* sont
des expressions régulières : U+={u1u2...un|∀ i, ui∈
U} représente l'ensemble des concaténations un nombre quelconque de fois (au
moins une) d'éléments de U, et U*=U+∪{ε} est la même
concaténation, y compris 0 fois (ce qui donne la chaîne vide).
Le symbole
ε joue le rôle d'élément neutre pour la
concaténation : pour tout symbole
w∈ V,
w.
ε=
ε.
w=
w.
A titre d'exemple, l'automate de la figure
4.4
construit sur le vocabulaire
V={
a,
b} reconnaît le langage
constitué d'un nombre quelconque (éventuellement nul) de symboles
a
suivi d'un nombre quelconque mais non nul de symboles
b (parce que
tout chemin, pour passer de l'état initial 1 à l'état final 2,
doit obligatoirement emprunter la transition étiquetée par
b entre
ces deux états). Il peut être représenté par l'expression régulière :
a*b+.
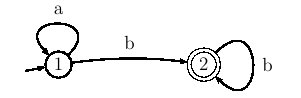
Figure 4.4 : un automate fini dont le langage est a*b+
Le langage
a*b+ est un
langage infini, puisqu'il contient
un nombre non borné de mots différents :
a*b+={
b,
ab,
bb,
aab,
abb,
bbb, ...}. On voit que la puissance des automates finis et des
expressions régulières vient de ce qu'ils permettent de
caractériser un nombre infini de mots différents à l'aide d'un nombre
fini d'éléments. Néanmoins, si les langues naturelles contiennent un
nombre infini d'unités lexicales, c'est grâce au fait que les
morphèmes lexicaux constituent une liste ouverte (et qu'on peut
toujours inventer de nouveaux mots) et non grâce à l'expressivité des
affixations, telles qu'on peut les exprimer dans des automates finis.
Tout langage régulier peut être exprimé sous la forme d'une (ou
plusieurs) expression(s) régulière(s) (et inversement). Passer d'un
automate à une expression régulière ou inversement n'est pas toujours
simple. Le langage (fini) reconnu par l'automate morphologique précédent, en
figure
4.3, peut être représenté par exemple par l'expression régulière complexe suivante :
(in|
ε).(imit|analys|désir|nomm).((é.(
ε|e|s|es))|able(
ε|s))
| 2.4 |
Sites Web et programmes gratuits |
|
De nombreux sites réalisent en ligne des traitements se situant au
niveau des mots ou des morphèmes.
-
comptages, statistiques (à partir de textes français):
- décompositions morphologiques :
- étiquetages en catégories :
- repérage des entités nommées :
Parmi les programmes libres et gratuits qui illustrent les notions
introduites dans ce chapitre, on peut citer Unitex, logiciel fondé
sur les automates et les RTRs (cf. chapitre suivant). Quand on charge
un texte avec Unitex, ce dernier lui applique un certain nombre de
pré-traitements (normalisations, comptages, lemmatisations, etc.) qui,
tous, sont réalisés à l'aide d'automates facilement visualisables et
modifiables. L'utilisateur peut aussi écrire ses propres automates
pour, par exemple, effectuer la recherche d'une expression régulière
dans un texte :
www-igm.univ-mlv.fr/~unitex/