19.1 Introduction
There is very little agreement about what might constitute a dependency grammar. What does a dependency grammar look like? How can we process it efficiently? What is the essence of dependency parsing? In this chapter, we attempt to provide an answer to these questions. Our formulation should by no means be construed as the definitive word on the issue. Rather, we propose to demonstrate how the problem can be approached in a declarative, constraint-based fashion, that leads naturally to an elegant and efficient implementation.
The presentation will proceed in a manner similar to our treatment of dominance descriptions in Section 16.2: we will develop a formal characterization of what constitutes a valid dependency tree. This formalization, modulo details of syntax, can then be viewed as a constraint-based program.
Again, it will turn out that simple set theory is a wonderful modeling tool, and permits to succinctly capture the more complex properties of the formal models of interest. We are going to use it a lot; in fact, almost exclusively! Computationally speaking, this is also good news since Oz directly supports sets and constraints on sets.
Before we dive into the formal treatment, let us first briefly motivate the dependency grammar approach. One reason you may find dependency grammar attractive is that it doesn't loose its marbles when confronted with a language with free word order (freer than english). Consider the sentence below:
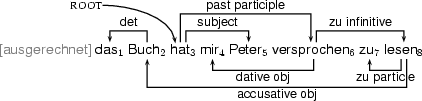
What is challenging in this sentence1 is the very liberal word order. Peter, the subject of the main auxiliary verb hat, appears between the past participle versprochen and its dative object mir. The infinitive clause zu lesen is extraposed to the right out of the main clause, while its own accusative object is moved, for purposes of emphasis, to the very front of the sentence. As illustrated in the figure below, such a sentence requires an analysis with crossing edges.
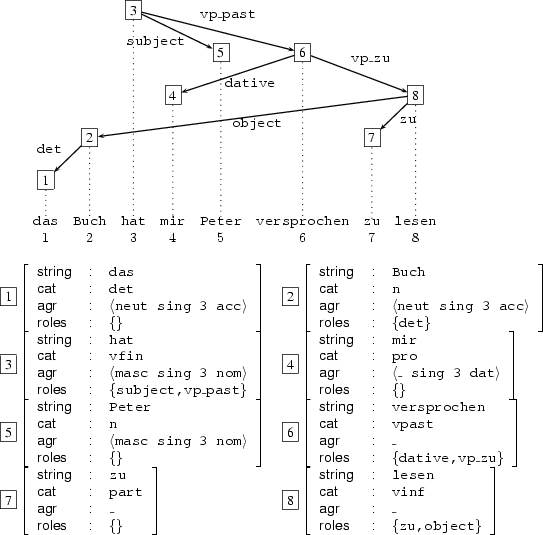
Its dependency parse tree will traditionally be represented by a collection of attribute value matrices (AVMs) where the boxed integers represent coreference indices (a conventional notation in computational linguistics). These AVMs form a feature structure organized into a dependency tree where the root is node 3.
In the remainder of this chapter, we are going to turn our attention entirely to the study of such collections of AVMs. We are going to make precise the conditions required for them to be considered valid dependency analyses.