


|
|
|
Dans ces deux types enregistrements, l'axe horizontal marque le déroulement du temps. L'oscillogramme traduit par le mouvement d'une aiguille les variations de l'onde acoustique, tandis que le spectogramme enregistre, pour chaque fréquence sonore (déroulées sur l'axe des ordonnées), l'amplitude (en décibels) de cette fréquence, et la traduit dans l'intensité du pixel correspondant. La phonétique acoustique étudie les propriétés de diagrammes de ce genre.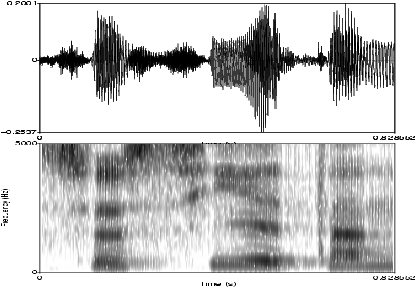
Figure 3.1 : oscillogramme (en haut) et spectrogramme (en bas) d'une onde acoustique correspondant à la prononciation d'un morceau de phrase
|
|
|
|
| Gall, amant de reine, alla, tour magnanime, |
| Galamment de l'arène à la tour Magne, à Nîme, |
| Dans ces meubles laqués, rideaux et dais moroses |
| Danse, aime, bleu laquais, ris d'oser des mots roses. |
Ici aussi, ce sont plutôt des critères syntaxico-sémantiques qui devraient aider à choisir la bonne prononciation. Enfin, pour restituer à un système artificiel une diction "naturelle", il faut aussi tenir compte des règles de prononciation (quand un "e" est muet ou pas, etc.), de la ponctuation, des enchaînements et des liaisons. La synthèse d'une certaine prosodie, voire d'émotions quand le texte le justifie, est aussi assez délicate.Note aux élus qui au Conseil président et au président de la république d'Egypte
Il faut que nous adoptions pour les adoptions des mesures favorables afin que cesse un trafic dénoncé par M. Jean, célèbre reporter. Reporter ce débat serait pure folie. "Dans notre pays il devient impossible d'adopter un fils tant les fils des lacs de l'administration sont troubles comme les eaux des lacs et étriqués comme un jean, dit Jean, et, pour les démêler, vous en suez. Or, à Suez, une mater et les soeurs d'un couvent couvent un réseau à mater. Elles échangent des orphelins mal nourris contre dations." Nous dations de 1995 ces propos dans notre précédent rapport. Intervenir devient urgent, comme urgent ces options à prendre. Il faut que nous options pour l'abolition de ce genre d'exécutions ; nous exécutions des contrôles dans plusiseurs de ces établissements d'un seul jet ; nous affrétions un jet chargé de rations de riz ; nous ne rations pas une occasion de stopper ce trafic influent dont les chefs influent sur vos relations (nous en relations hier encore dans la presse). Donc, il convient que les élus convient les autorités à affronter les problèmes là où ils résident. Un résident confirme : si nous intentions un procès, nos intentions seraient louées puisqu'elles coïncident avec le désir (coïncident à la venue du pape) de démanteler cette mafia. Que nous transitions par Rome s'impose donc sans transitions. Comment se fier à celles qui se parent de cornettes, content des sornettes et violent les lois, et rester un fier citoyen, voire parent adoptif et content de l'être, mais non violent ?
|
|