Explorer3D a été profondément modifé afin de permettre une manipulation multi-vues interactive. Ce mécanisme se décline en plusieurs aspects : d’une part le fait de pouvoir ouvrir simultanément plusieurs fenêtres de visualisation, et d’autre part le fait de pouvoir suivre les objets sélectionnés entre ces différentes vues.
Par vue nous désignons ici la fenêtre 3D. On peut ouvrir plusieurs fenêtre 3D pour un même jeu de données, notamment pour les raisons suivantes :
Certaines commandes sont globales et vont affecter toutes les vues : il s’agit par exemple de la coloration de sobjets (notamment pour identifier les classes).
En revanche, beaucoup de commandes n’ont pas vocation à s’appliquer globalement, telles les opérations de clustering, les crops, etc., qui s’appliquent sur une vue donnée.
Ceci conduit à définir la notion de vue active : la vue active est la vue sur laquelle s’appliquent les commandes non globales. Comment désigner et identifier cette vue?
On peut choisir la vue à activer en donnant le focus à sa fenêtre. Une fois la vue active, sa fenêtre est bordée de rouge (voir figure 21). Une vue reste active tant que l’on ne désigne pas explicitement ou implicitement une nouvelle vue active. Lorsque l’on crée une nouvelle vue, celle-ci devient automatiquement active. A tout instant, il y a au plus une vue active.
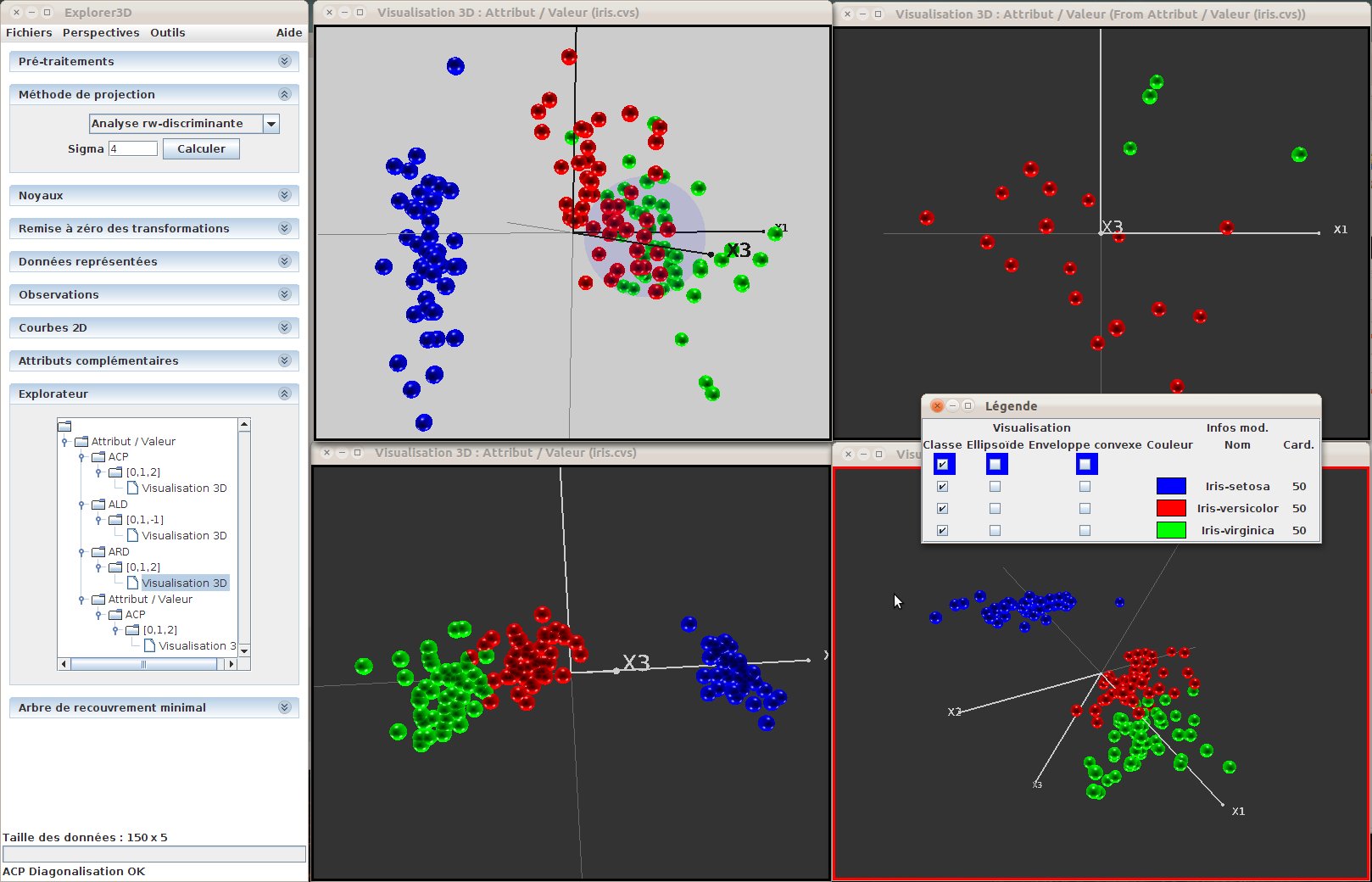
Figure 21: Plusieurs vues simultanées. La vue active (en bas, à droite) est repérée par sous liseré rouge. On peut remarquer ici l’utilisation de commandes globales (la coloration en fonction des classes) et locales (la mise sur fond clair de la vue en haut à gauche)
La liste des vues disponibles peut être consultée dans la sous-fenêtre “Explorateur” de la fenêtre principale. Cette sous-fenêtre contient une arborescence, avec à la racine la source de données utilisée, puis la méthode appliquée sur cette source, enfin la projection effectuée (indiquant les axes de projection choisis), et enfin la vue calculée sur cette base. La vue active est mise en avant dans cette arborescence. Le fait de cliquer sur l’une des vues dans l’arborescence rend celle-ci active. La figure 22 présente l’explorateur de vues. On peut constater ici que l’on manipule des données décrites sous-forme “attribut / valeur”. On peut constater que pour l’ACP on a projeté suivant les trois axes principaux. On pourra observer ici les axes de projection de la seconde méthode. Le troisième axe, ici, vaut “-1”, ce qui indique que l’on n’a pas de projection suivant le troisème axe : tous les objets sont projetés dans le plan x-y.
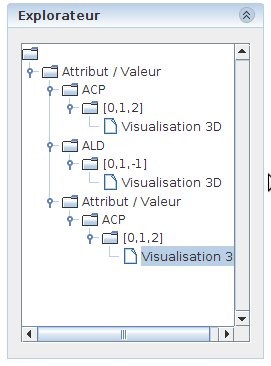
Figure 22: L’explorateur des vues. Ici, nous avons une source de données de type “Attribut / Valeur”, sur laquelle on a appliquer une projection par ACP et une par ALD; un zoom local a été appliqué sur une des vues (on voit qu’il y a une source “Attribut / Valeur” dans les descendants de la source principale, signe d’une sélection d’un sous-ensemble d’objets. C’est la vue correspondant au zoom local qui est active (fond gris)
Les objets sélectionnés apparaissent en surbrillance. La liste des objets sélectionnés est transverse à toutes les vues. En d’autres termes, on sélectionne dans une vue et on voit la surbrillance dans toutes les vues. Cela peut être assez utile pour rechercher un même objet dans les différentes vues, ou pour observer la dispersion d’un groupe d’objets à travers des projections diverses.
Il est possible, par le biais des options, d’activer l’affichage d’un tableau contenant les informations complémentaires des objets manipulés. Comme défini précédement, les attributs “complémentaires” sont les informations fournies mais non utilisées dans le calcul de la projection spatiale. Il peut s’agit par exemple de la classe si une classe est fournie, d’un nom de fichier image associé, etc. Plusieurs attributs peuvent être fournis.
Ce tableau contient par défaut tous les objets de la scène 3D, triés suivant leur ordre dans le fichier de données. Par défaut, tous les attributs complémentaires apparaissent. On peut choisir les attributs affichés grâce au menu Visibilité colonnes / attributs complémentaires. Il est également possible de faire apparaître les coordonnées de projection des objets, grâce au menu Visibilité colonnes / coordonnées de projection. Par défaut, ces colonnes ne sont pas affichées.
Il est prévu dans une version ultérieure de pouvoir afficher les attributs ayant servi à calculer la projection. Toutefois, le nombre d’attributs étant potentiellement large, la mise en oeuvre technique nécessite réflexion.
Il est possible de sélectionner les objets dans cette liste, et de réduire les lignes visibles aux seuls objets sélectionnés (voir fig. 23). Pour cela, cocher “Filtrer (sélection)” dans le menu “Visibilité lignes”.
Le mécanisme de sélection est décrit en section 6.4 .
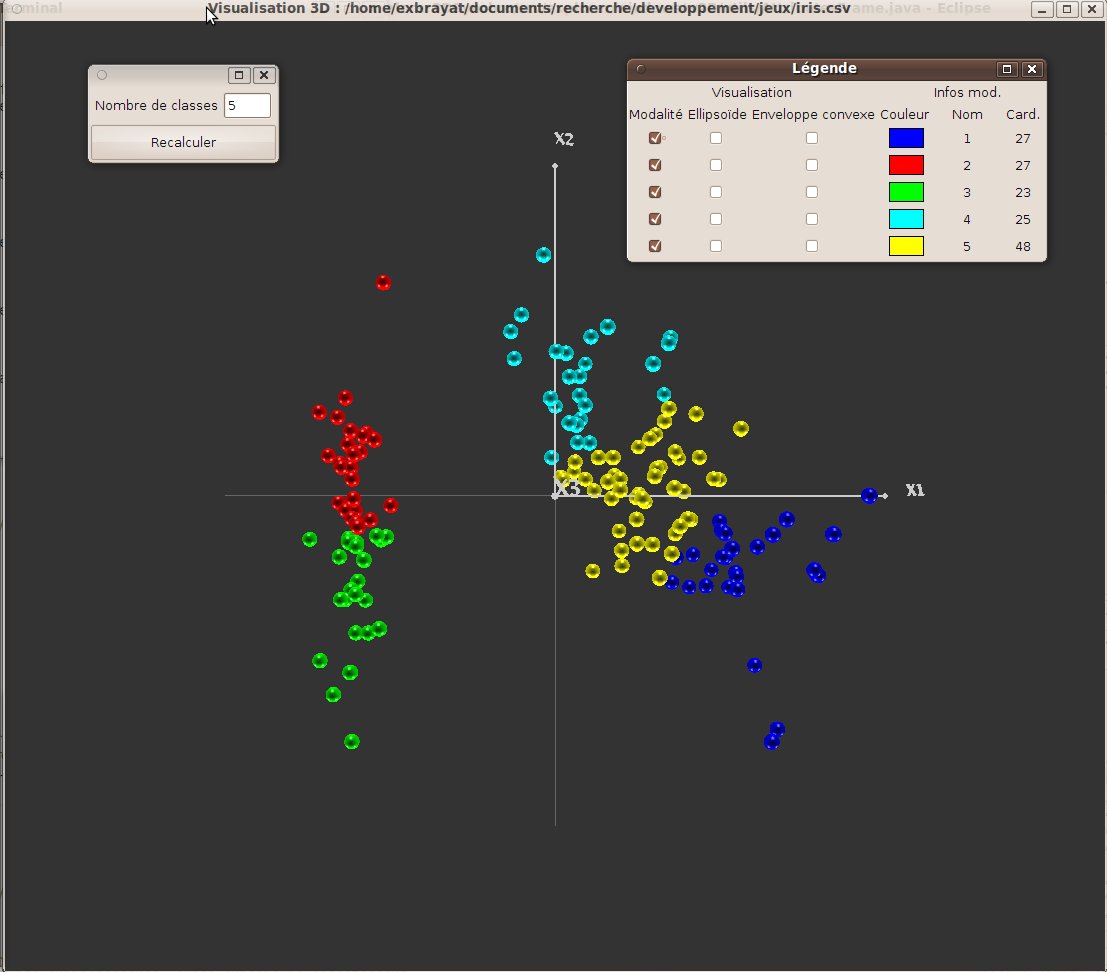
Plusieurs méthodes de classification sont désormais disponibles. Elles sont accessibles à partir de la perspective “classification” (voir fig.24) qui peut être ouverte à partir des menus. Les méthodes de classification proposées ont un défauts commun : elles sont plus ou moins instables, et d’une exécution à l’autre, les groupes générés peuvent changer. Il est donc conseillé de les relancer plusieurs fois (bouton ”recalculer”) afin de se faire une meilleure idée de la stabilité des groupes (notons que le bouton “recalculer” permet aussi, pour certaines méthodes, de relancer la classification automatique avec de nouveaux paramètres, comme un nombre de groupes différents).
à l’ouverture
après choix d’une méthode
Figure 24: Fenêtre “classification”
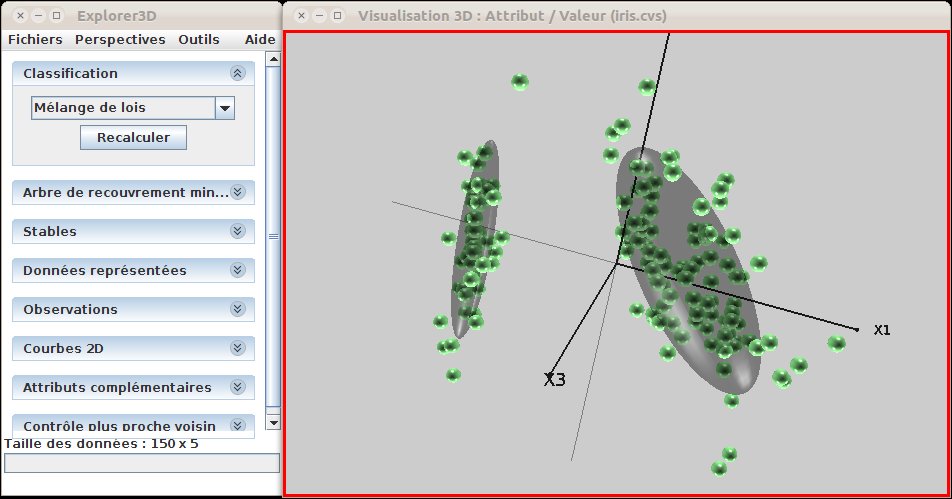
La fonction de clustering par mélange de lois considère que la répartition spatiale des objets se fait selon un ensemble de lois (multi) normales. On cherche donc à calculer les lois sous-jacentes, et on les visualise sous formes d’ellipsoïdes centrées sur les centres des lois et étirées suivant les directions et écart-type de celles-ci (cf figure 25). La méthode implantée calcule automatiquement le nombre de lois.
Dans cette méthode classique, on fixe un nombre de groupes, dont les centres sont initialement positionnés de manière aléatoire. Chaque objet est rattaché au centre le plus proche. Les centres sont déplacés jusqu’à obtenir un placement optimal, c’est à dire, dans ce cas, générant des groupes les moins dispersés possible. Dans l’implantation proposée, l’utilisateur peut choisir le nombre de centres, et donc le nombre de groupes générés.
Les nuées dynamiques étant instables, un second outil a été implanté, accessible à partir de la sous-fenêtre “Stables”. Un stable est un ensemble d’objets qui sont toujours classés ensemble (ici, par les nuées dynamiques). Dans cet outil, on choisi le nombre de classes (comme pour kmeans), mais également le nombre de fois où kmeans est exécutée. Au terme de ces calculs, on obtient un ensemble de classes, chacune contenant des ob jets qui ont été classés ensemble lors de toutes les exécutions de kmeans.
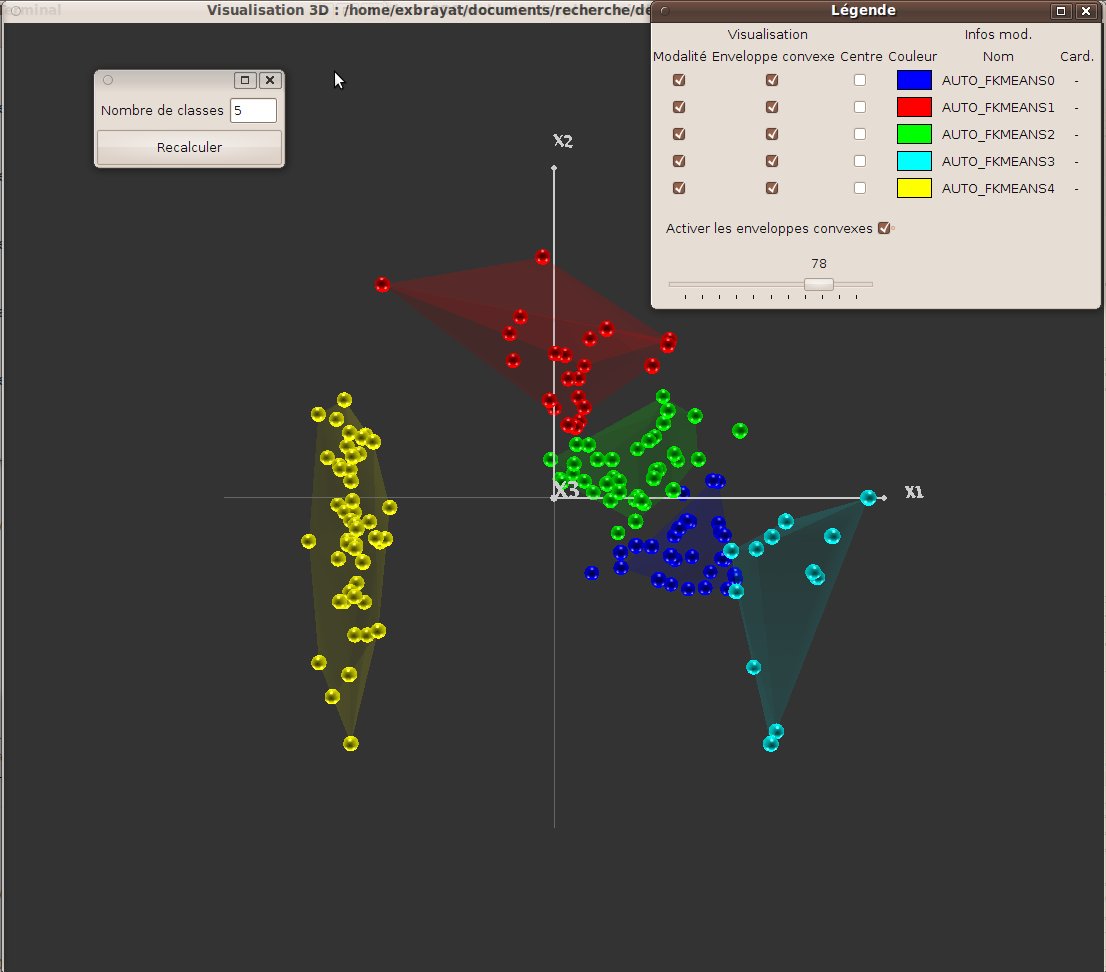
Il s’agit d’une méthode dérivée de la précédente, à ceci près que chaque objet appartient à tous les groupes, avec un degré d’appartenance lié à sa distance au centre du groupe. Comme précédemment, l’utilisateur peut choisir le nombre de centres. L’intérêt d’une telle méthode consiste à laisser plus de marge d’interprétation à l’utilisateur. Elle est en revanche plus difficile à visualiser. Nous avons donc développé une technique de visualisation spécifique. Il convient de faire apparaître différentes informations : le groupe principal d’un objet, mais également les objets appartenant “à un certain point” à chaque groupe. Nous avons donc développé une visualisation reposant sur la technique des enveloppes convexes (voir figure 27) : pour chaque groupe (ou un sous ensemble de groupes sélectionnés), on fait apparaître l’enveloppe convexe convexe contenant tous les objets appartenant à un groupe “à au moins x pourcents”. Le seuil x peut être réglé dynamiquement par le biais d’un composant graphique, et l’on peut donc observer dynamiquement l’évolution des enveloppes en fonction de x. Il est à noter que cet outil peut également être utilisé lorsque la classification floue n’est pas fournie par un outil interne, mais directement dans les données transmises au logiciel (donc effectuée par un outil tiers).
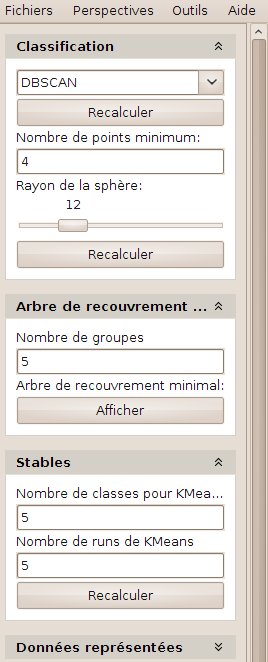
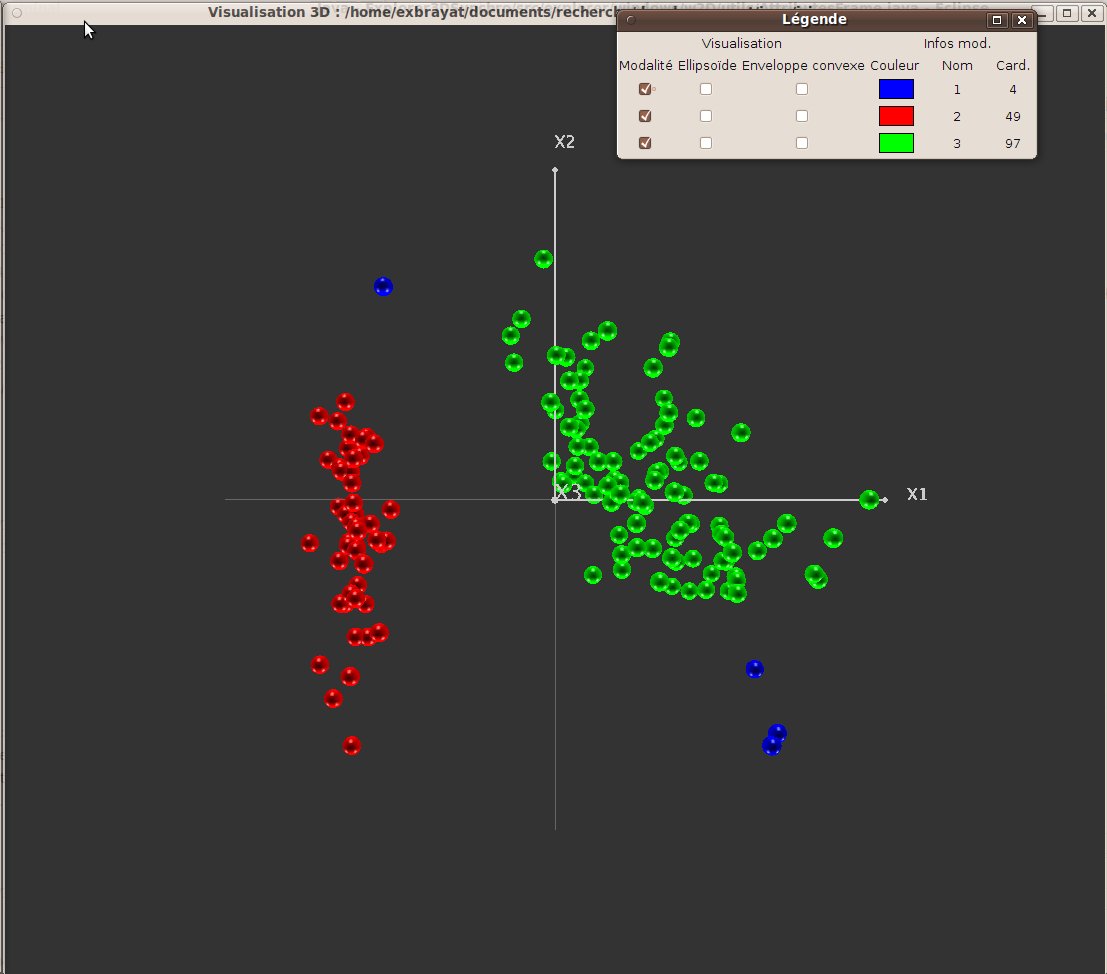
Contrairement aux techniques précédentes, qui fonctionnent suivant la distance au centre, et génèrent donc des groupes à structure sphérique, les techniques de classification par densité consistent à considérer que les centres de groupes sont les zones spatiales les plus denses. L’agrégation des objets aux groupes se fait ensuite par voisinage. De telles techniques sont utiles lorsque les objets sont structurés par zones de fortes densité, et suivant des formes complexes.
Lors de l’utilisation de cette méthode, on choisit deux paramètres : le rayon dans lequel on considère les voisins, et le nombre minimum de voisins pour considérer que l’on se trouve dans un groupe. Afin d’aider l’utilisateur à régler le rayon, une sphère est visualiser au centre de la vue 3D; son rayon correspond au rayon utilisé pour le clustering.
La figure 28 représente le résultat d’une telle méthode. Notons que le premier groupe correspond aux objets isolés. Il peut éventuellement être vide.
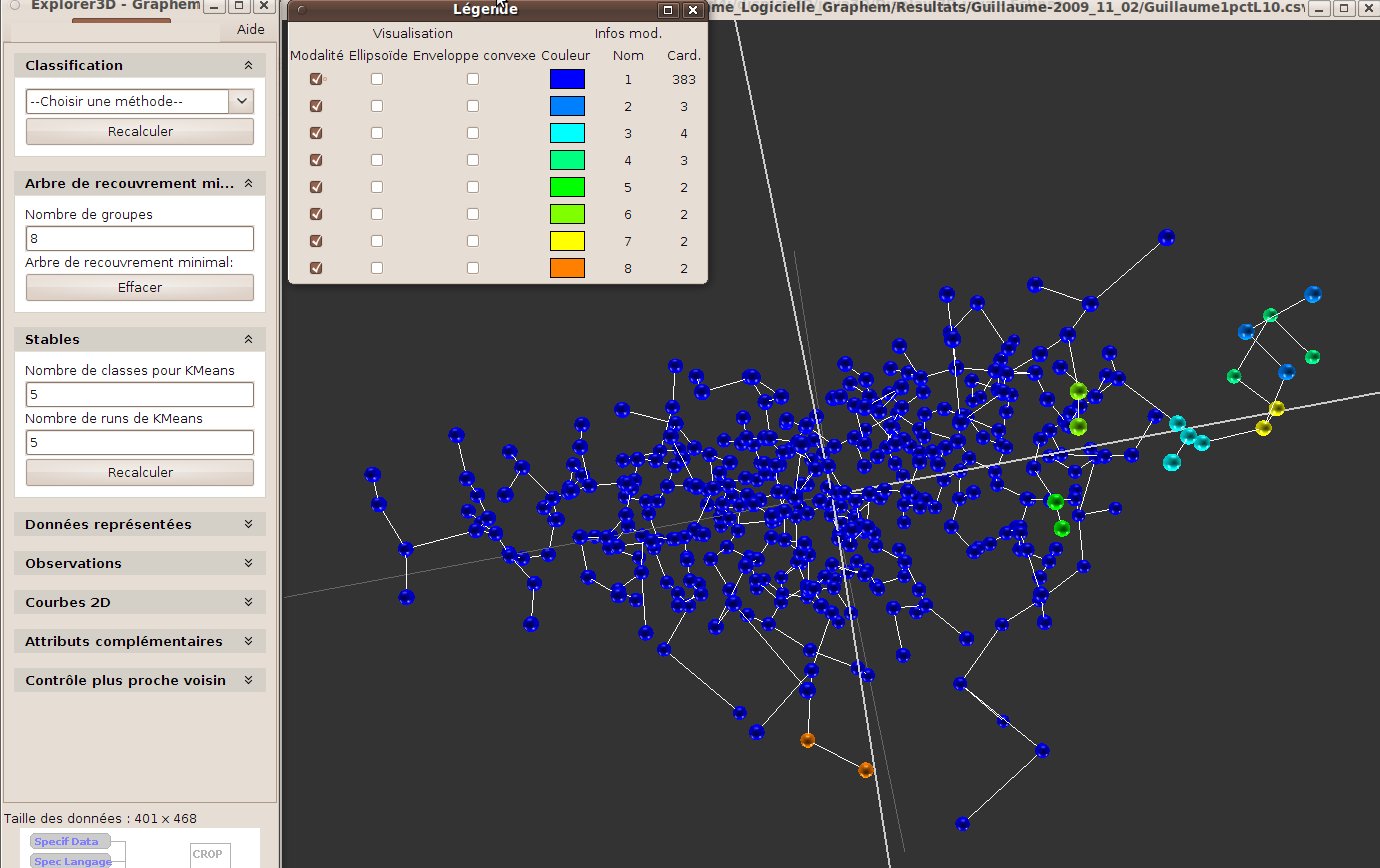
L’arbre minimal de recouvrement est un arbre reliant les objets visualisés. Sans rentrer dans les détails, dison que cet arbre matérialise les proximités entre objets, et que deux objets sont reliés s’ils sont “les plus proches”. Visualiser cet arbre permet donc de voir comment s’organise les objets de proche en proche. Un lien long montrera que l’on a des groupes éloignés, etc.
Une classification hiérarchique consiste à regrouper les objets de proche en proche. On commence par regrouper les deux objets les plus proches. Puis on recommence en cherchant les éléments les plus proches, qu’ils s’agisse de deux objets, de deux groupes déjà constitués, ou d’un objet et un groupe. Les distances impliquant un ou deux groupes peuvent être calculées de plusieurs manières. Nous avons retenu celle reposant sur la notion de “saut minimal”: la distance entre un objet et un groupe est la distance entre l’objet et l’objet du groupe qui en est le plus proche. Entre deux groupes, il s’agit de la distance entre les objets les plus proches de ces deux groupes. On produit ainsi un arbre de classification, également appelé dendrogramme. Il s’agit du type de structure rencontrée pour décrire, par exemple, la classification des espèces. En général, cette structure est représentée à plat. Ici, elle est superposée à la vue 3D (voir fig. 29).
On voit qu’il existe un lien entre les concepts d’arbre de recouvrement minimal et de classification hiérarchique. Le nombre de classes est fixé par l’utilisateur. Il revient à couper l’arbre, en partant du sommet, afin d’avoir un nombre de branches égal au nombre de classes souhaitées.
Il s’agit d’une fonctionnalité expérimentale que nous vous invitons à tester. Cet outil, accessible à partir des menus (Outils/Interaction), permet de poser des contraintes sur la proximité ou l’éloignement spatial de divers objets, et donc de reconfigurer l’espace de projection afon de respecter au mieux les nouvelles contraintes (tout en offrant par ailleurs une projection limitant les distorsions). Nous vous invitons dans un premier temps à manipuler l’outil “Comparaison”.
Plusieurs contraintes peuvent être saisies pour un même calcul. Il est toutefois déconseillé, pour l’instant, d’ajouter beaucoup de contraintes, ou de mettre des contraintes opposées.
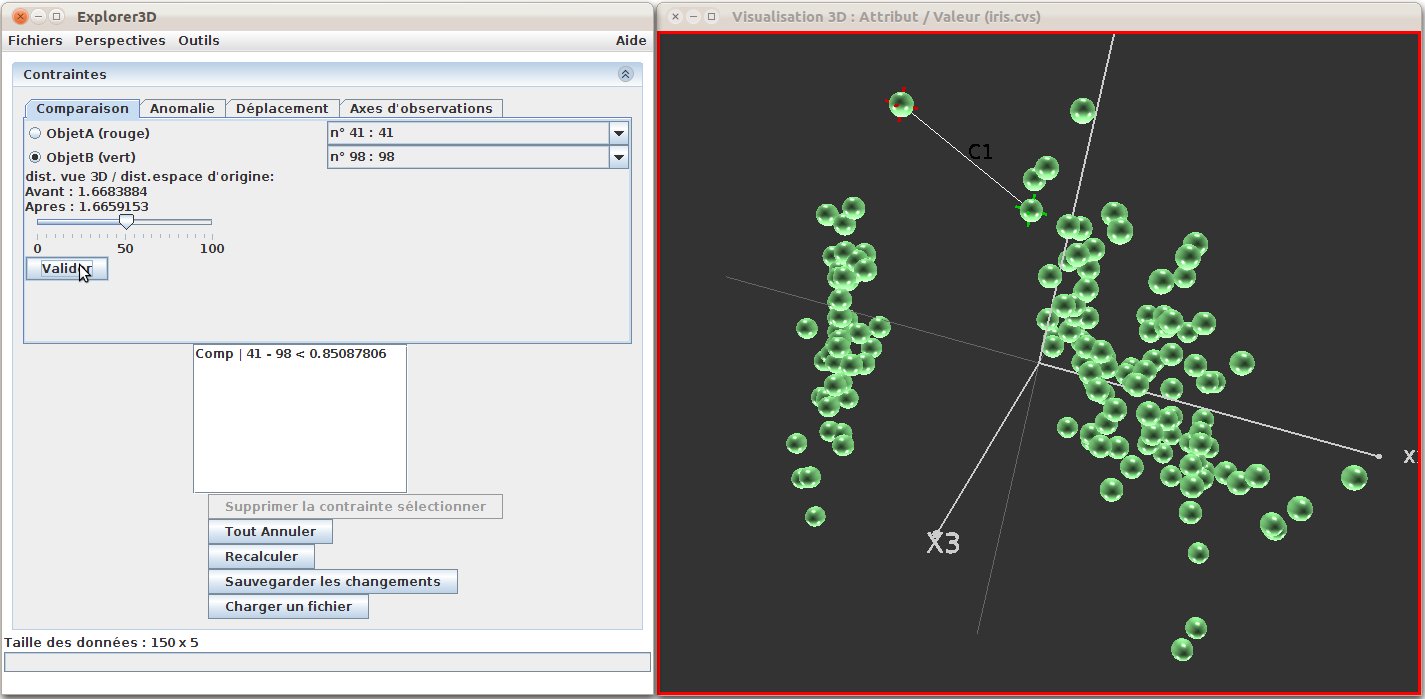
Figure 30: Correction de distance : On peut voir les deux points concernés dans la vue 3D (point A-41 : croix rouge; point B-98 : croix verte). La contrainte saisie demande que les deux points soient rapprochés (slider de la fenêtre de gauche, et contrainte explicite exprimée en dessous (Comp | 41-98 < 0.85...)
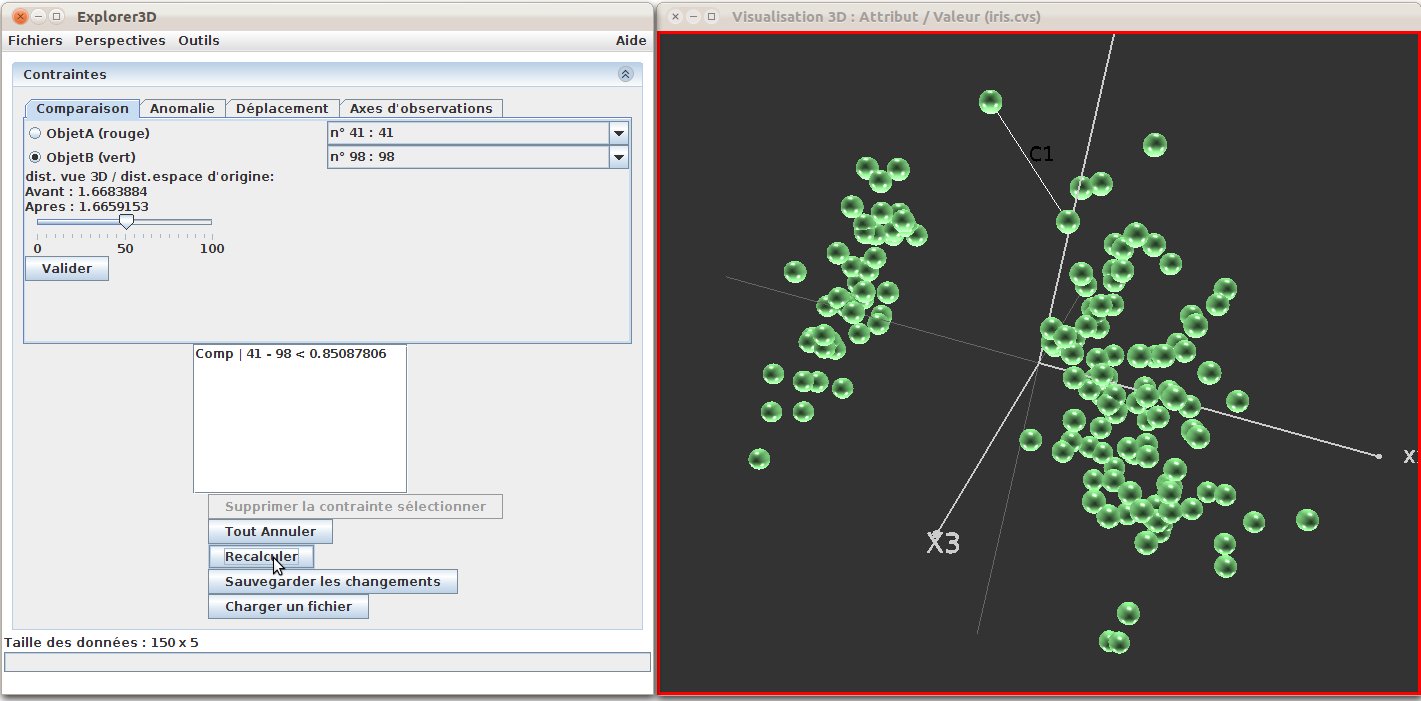
Figure 31: Correction de distance : la contrainte a été appliquée. On peut voir que la projection a changé et que les deux points concernés ont été rapprochés.
L’outil Anomalie permet de modifier le positionnement relatif de trois objets. Pour ce type de reconfiguration, on manipule trois objets A, B et C. Le principe est de modifier la distance entre A et C relativement à la distance entre A et B. En d’autres termes, il s’agit de rapprocher ou d’éloigner C par rapport à A, de manière à ce qu’il soit plus proche ou plus lointain de A que B.
On procède comme précédemment pour sélectionner les objets.
L’idée de ce type de reconfiguration consiste à modifier le voisinage d’un objet. Cette méthode est assez complexe et son utilisation est déconseillée pour l’instant. Le mode opératoire est le suivant : Il faut commencer par définir le voisinage : on sélectionne les objets du voisinage un per un puis on clique sur “ajouter”. Ensuite on coche “objet à déplacer”, et on indique l’objet que l’on souhaite éloigner de ce voisinage. Il suffit ensuite, comme dans les cas précédents, de cliquer sur “Valider”, puis sur “Recalculer”.
Afin d’observer un sous-ensemble d’objets, il est possible de mettre en place des axes d’observations. Pour cela, on se rend dans l’onglet “Axes d’observation” (voir figure 32), puis on sélectionne les deux objets formant les extrémités de l’axe (ou, dans un sens plus strict, du segment) observé. On règle le nombre de points à afficher (par défaut, 10), et on clique sur “Valider”. Les dix objets les plus proches du segment (et se projetant sur celui-ci) sont alors sélectionnés, et un tableau indiquant leur numéro et leurs attributs complémentaires apparait (fenêtre “caractéristiques...”). On peut gérer simultanément plusieurs axes d’observation, et les dissimuler / supprimer grâce à la fenêtre “Axes:”
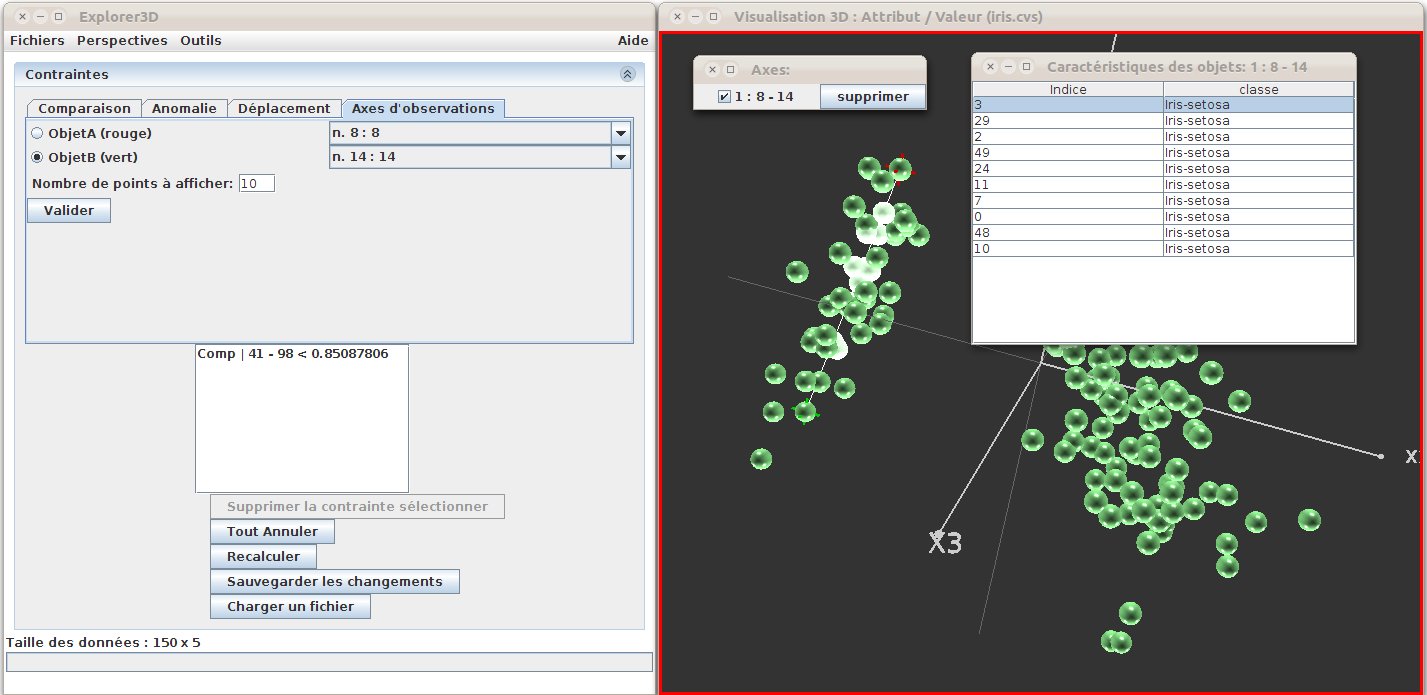
Figure 32: Mise en place d’un axe d’observation. On observe les dix objets les plus proche de l’ ”axe” 8-14.
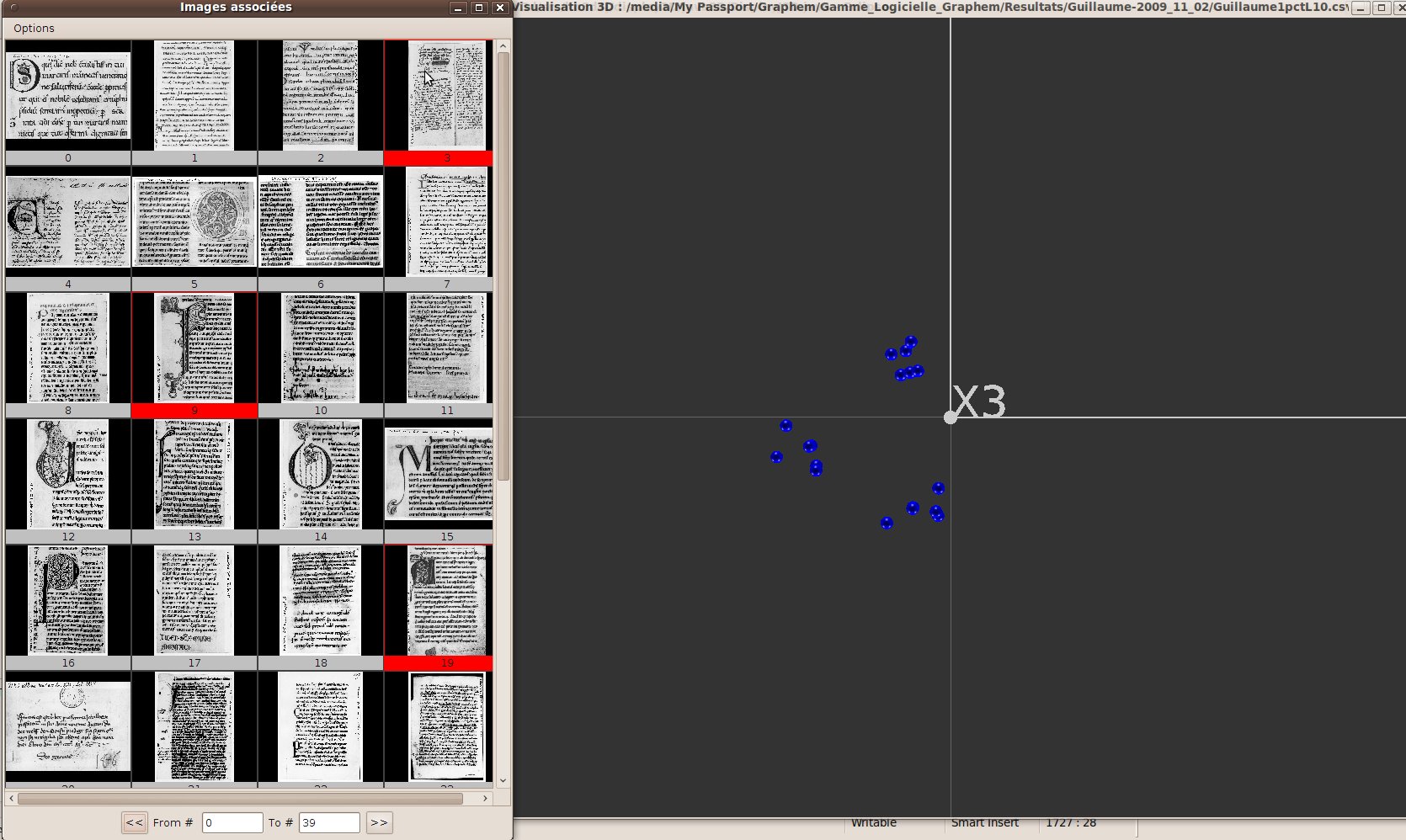
Afin de rendre l’espace de projection plus lisible, il est possible de ne faire apparaître qu’un ensemble d’objets choisis à partir des images associées. Pour cela, il faut bien entendu avoir défini l’attribut complémentaire correspondant aux images associées. Il suffit ensuite de cocher l’élément “Exploration à partir des images” dans le menu “Outils”. Les objets sont alors tous retirés de la vue 3D (ils sont rendus invisibles). Une fenêtre “Images associées” s’ouvre dans laquelle les images apparaissent (fig. 33). L’utilisateur choisit les objets qui l’intéressent soit grâce à la liste déroulante située en haut de la fenêtre (onglet “Liste” + validation), soit en saisissant directement son nom (onglet “Nom” + validation). A chaque ajout, l’image correspondante est affichée et l’objet est réaffiché dans la scène 3D. Lorsqu’une image est cliquée, elle est considéré comme sélectionnée, et il en va donc de même de l’objet correspondant qui est placé en surbrillance dans la fenêtre de visualisation. On peut sélectionner plusieurs images. Pour désélectionner une image, il suffit de recliquer dessus.
L’utilisateur peut choisir de visualiser les voisins, dans l’espace, de chaque objet exploré à partir de son image: lorsqu’une image est sélectionnée, elle apparaît, ainsi que ses “n” plus proches voisins, “n” étant fixé à 0 par défaut. Le nombre de voisins affichés et réglés dans l’onglet “Voisins”. Si l’image est désélectionnée, ses plus proches voisins sont aussi dissimulés.
Cette exploration pourra également être superposée à l’option générale “Affichage dynamique des images”, qui permet de visualiser une image (dans la vue 3D) lorsque le pointeur de la souris s’arrête sur l’objet correspondant.
Les SVM ou séparateurs à vaste marge sont un outil de classification cherchant à séparer au mieux deux catégories d’objets. Ils sont donc utilisés lorsque l’on connait la classe d’au moins une partie des objets.
Au plus simple, la séparation entre les deux groupes est un plan, tel que de chaque côté on trouve uniquement les objets d’un groupe. De plus, ce plan est le plus éloigné possible des objets des deux groupes (il est donc, en quelque sorte, “médian”). Une séparation aussi simple n’étant pas toujours disponible, on peut tolérer une marge d’erreur (quelques objets du mauvais côté) et/ou utiliser un hyper plan situé dans un espace plus complexe que l’espace de description ou l’espace de projection. Pour cela, on a généralement recours à un noyau (voir section 7.7). Une fois l’(hyper)plan séparateur défini, on peut estimer le groupe d’appartenance des objets non étiquettés, suivant le côté ou ils se trouvent (et leur éloignement par rapport à l’(hyper)plan.
Par ailleurs, si l’on a plus de deux groupes, on peut soit définir des SVM entre deux groupes, ou entre un groupe et tous les autres.
Dans Explorer3D les fenêtres de manipulation des SVM sont accessibles à partir du menu “Perspectives/SVM”. Pour les utiliser, il faut auparavant avoir défini l’attribut de classe.
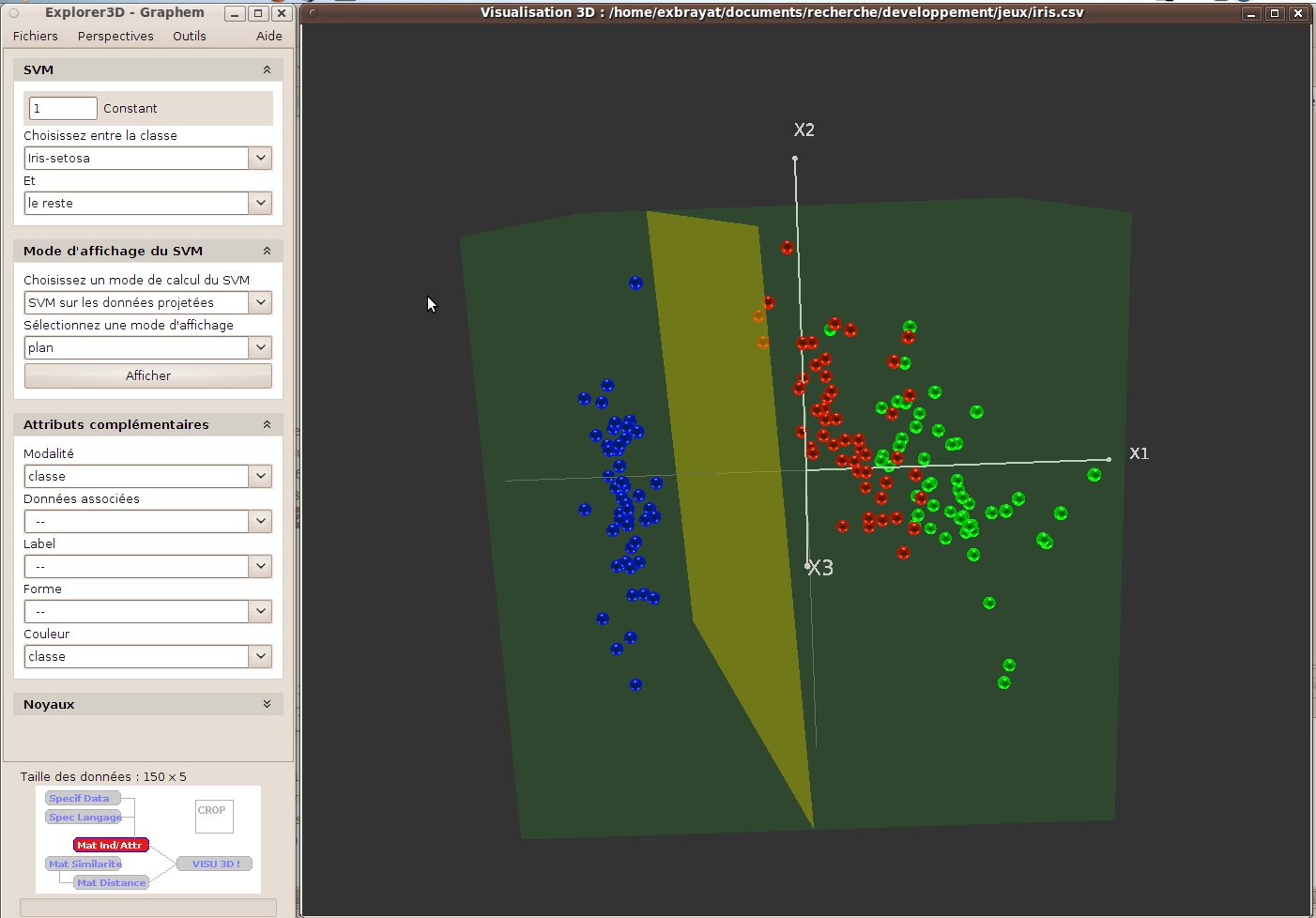
La figure 34 montre un exemple d’utilisation des SVM dans un cas simple : le très classique jeu de données “iris”. Nous pouvons voir dans la fenêtre de contrôle que nous avons tracé un SVM entre le groupe “iris-setosa” et le reste des objets, qu’il se fait sur les données projetées, et qu’il est visualisé dans la fenêtre 3D. Notons que la visualisation sous forme de plan ne peut se faire que pour les données projetées.
Les fonctionalités disponibles sont les suivantes :
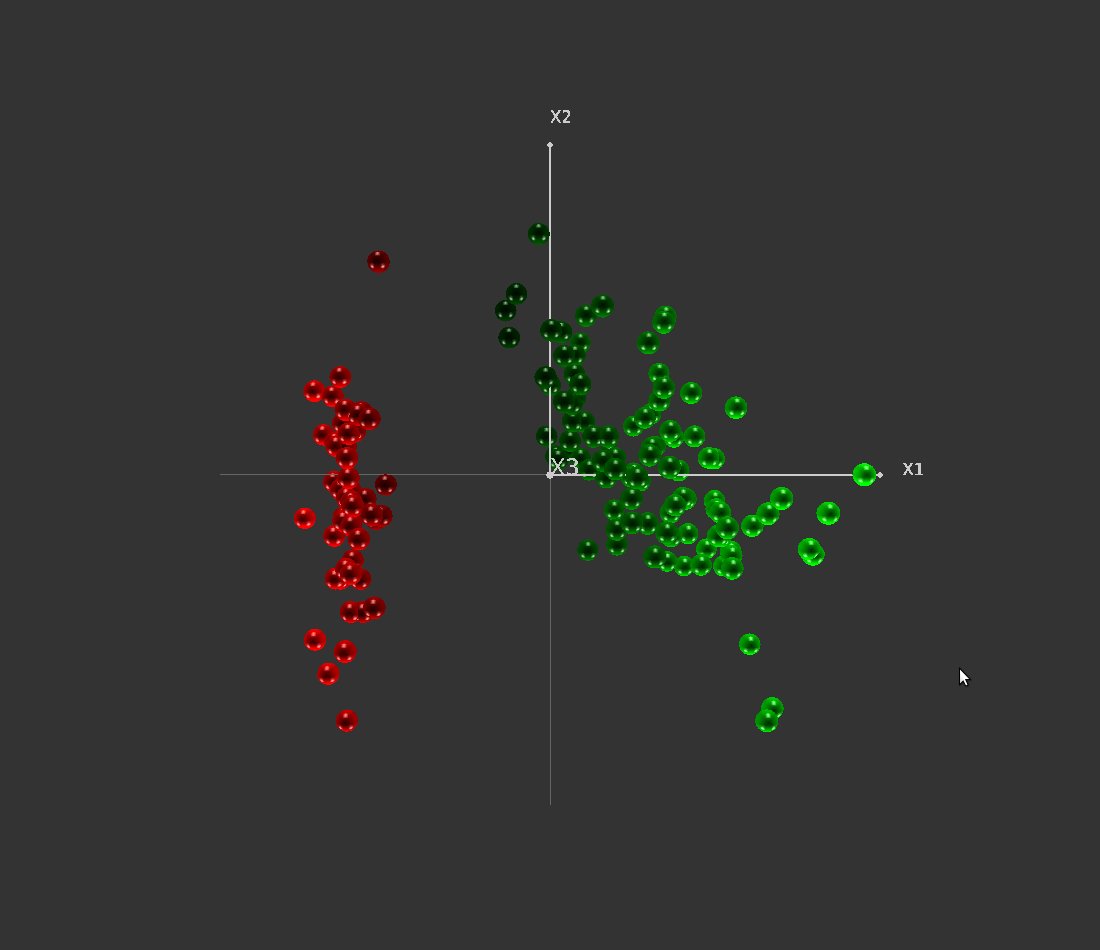
Avec le mode coloration, les objets sont colorés suivant un dégradé de couleur (rouge d’un côté, vert de l’autre). La figure 35 illustre ce mode de représentation.
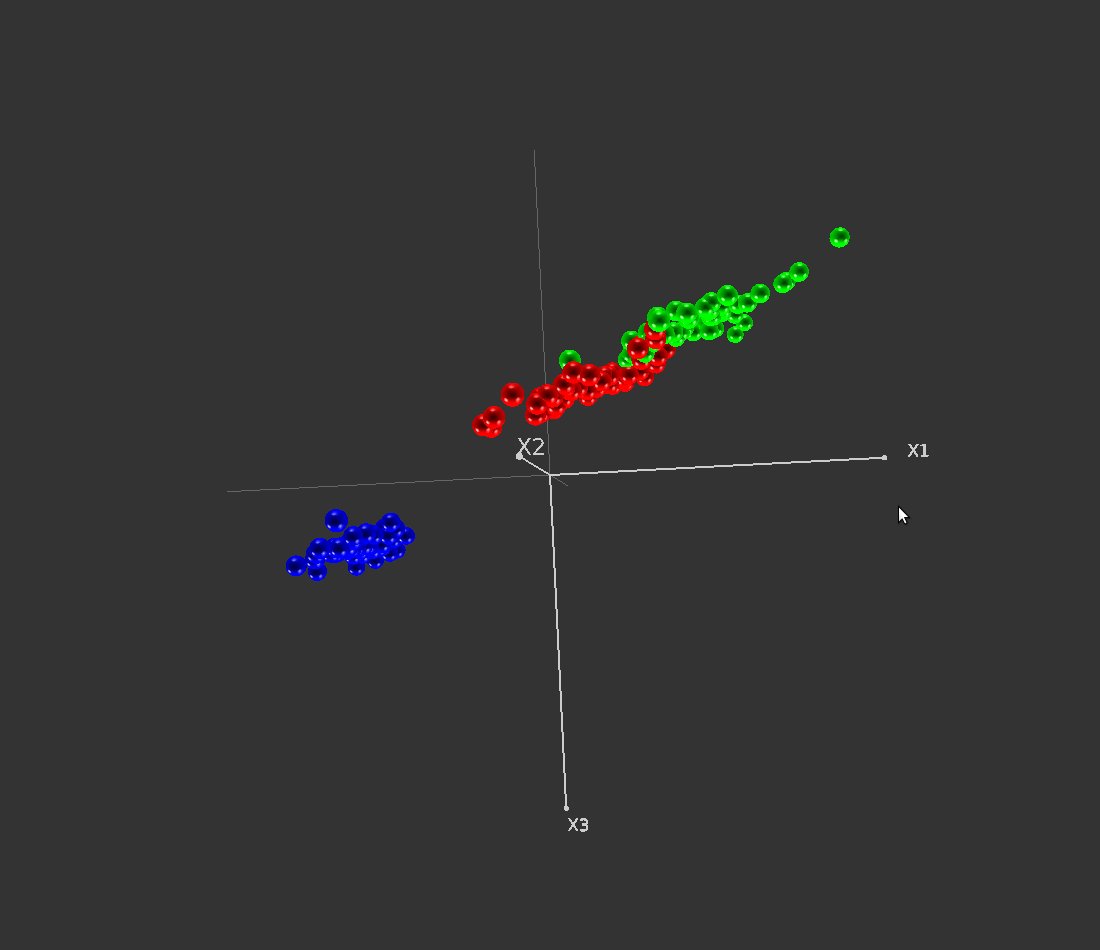
Avec le mode “remplacer 3ème axe”, la projection des objets ne se fait plus que suivant les axes “x1” et “x2”; leur coordonnée suivant l’axe “x3” correspond à leur éloignement de l’hyperplan séparateur. La figure 36 illustre ce mode de représentation.
Ces deux derniers modes peuvent être utilisés avec des SVM calculés dans l’espace d’origine ou à l’aide d’un noyau.
Les noyaux sont un outil puissant, dont l’usage en apprentissage automatique s’est principalement répandu grâce aux SVM. En effet, l’espace d’origine et l’espace de projection ne permettent pas toujours de trouver un hyperplan séparateur.
Les noyaux reposent sur l’idée de calculer de nouveaux attributs par combinaison des attributs existants. Ces combinaisons ne sont pour la plupart pas linéaires, mais doivent respecter certaines propriétés. Pour ces aspects techniques, on invitera l’utilisateur à consulter la bibliographie du domaine.
Les noyaux sont disponibles dans les perspectives “SVM” et “ND->3D”. La sous-fenêtre “Noyaux” permet de sélectionner un noyau, et le cas échéant de fixer les paramètres associés. Le noyau est choisi dans une liste déroulante. Lorsqu’un noyau est choisi, il s’applique à tout nouveau calcul de projection (clic sur le bouton “Calculer” de la sous-fenêtre “Méthode de projection”).
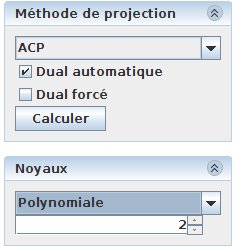
Figure 37: Fenêtre de contrôle des noyaux. On voit qu’un noyau polynomial a été choisi, avec un polynôme de niveau 2.
Nous donnerons uniquement et sommairement ici la liste des noyaux disponibles dans Explorer3D :
Notons que même l’utilisateur néophyte à la recherche, par exemple, d’une projection satisfaisante peut tester ces différents noyaux.
La sous-fenêtre “Courbes 2D” permet de visualiser diverses courbes complémentaires :
Cet outil permet notamment d’interfacer Explorer3D avec un autre logiciel, afin de visualiser les résultats de ce dernier. Cette fonctione est activée via la fenêtre des options (voir section 6.7). Explorer3D se met en écoute sur le port 50 000, et reçoit les commandes via le protocole json.
La liste des commandes disponibles est assez simple pour l’instant et se concentre sur la réception d’un tableau d’objets et sur la mise à jour de la classe d’appartenance de ces objets (et de la visualisation de celle-ci par coloration).
``msg'':''set-data''), puis la description des objets ("val" : [ [objet1], [objet2], ...]). Voici un exemple avec 4 objets à 4 dimensions chacun :
{
"val": [
[
0.09995818,
0.8450656,
0.31611204,
0.9885413
],
[
0.20870173,
0.6817836,
0.30197513,
0.20966005
],
[
0.95933825,
0.7643002,
0.23336774,
0.7409621
],
[
0.075930595,
0.12991834,
0.6995411,
0.092056274
]
],
"msg": "set-data"
}
``msg'':''set-classes''), puis le nombre de classes (``nbclasses'': valeur) et enfin la description des classes ("val" : [ [classe_objet1], [classe_objet2], ...]). Voici un exemple avec nos 4 objets; il y a 2 classes; les 3 premiers objets appartiennent à la classe 1, le dernier à la clase 0 :
{
"val": [
1,
1,
1,
0
],
"msg": "set-classes",
"nbclasses": 2
}
``msg'':''set-classes-fast'') et la liste des modifications. Celle-ci se présente sous forme d’un tableau ("val" : [ [classe_objet1], [classe_objet2], [saut_objets], ...]), dont l’encodage est le suivant : une valeur positive indique une nouvelle valeur de classe pour l’objet correspondant; une valeur négative indique un saut dans la liste des objets (objets dont la classe ne change pas). Voici un exemple avec nos 4 objets; la classe des deux premiers objets n’est pas changée (saut de 2). Le troisième passe en classe 0; la classe du dernier objet ne change pas (saut de 1).
{
"val": [
-2,
0,
-1
],
"msg": "set-classes-fast"
}
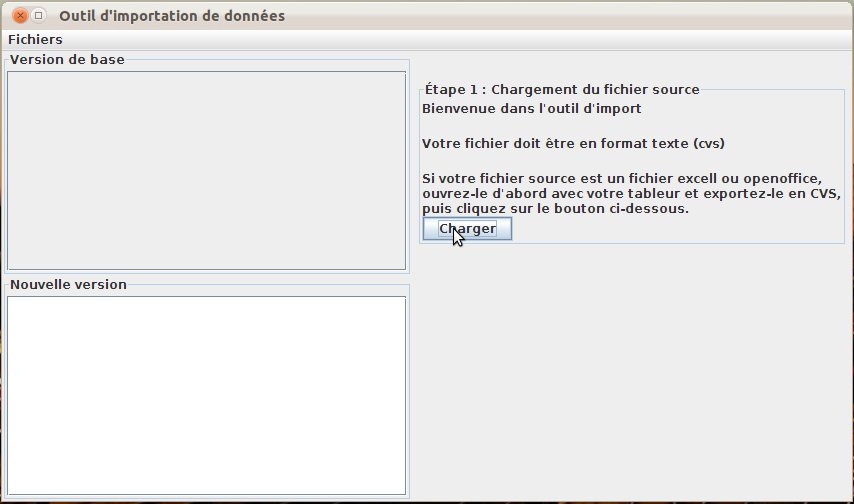
L’outil d’import est ouvert dans le cas d’un jeu de données non reconnu, ou directement par le menu “Fichiers / outil d’importation de données”.
Cet outil assez intuitif commence par chargement du fichier source (fig. 38); cette étape n’est explicite que dans le cas de l’accès via le menu.
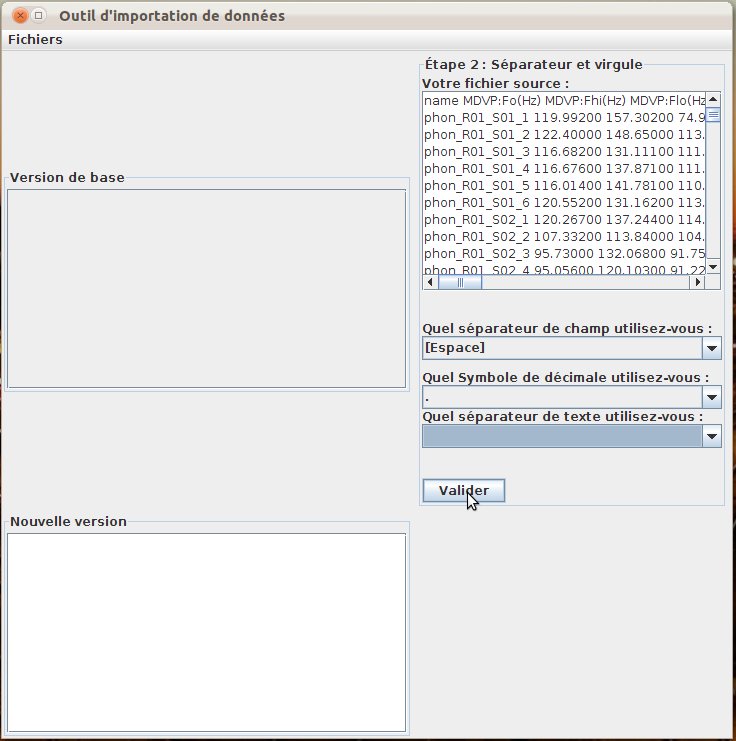
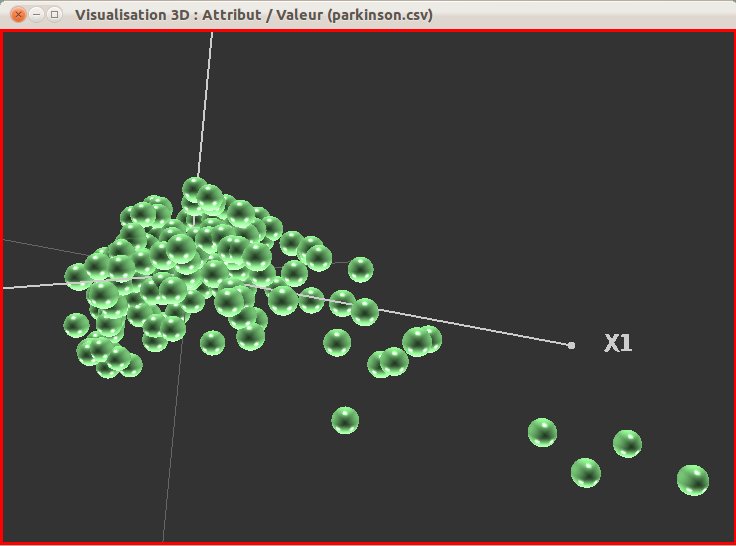
L’utilisateur indique ensuite les délimiteurs utilisés dans le fichier source : séparateur de champs, symbole de décimale et séparateur de texte (fig. 39). Une vue du fichier source est présentée durant cette étape. Le jeu de données utilisé pour cet exemple est le jeu “Parkinson” disponible sur le site de l’UC Irvine.
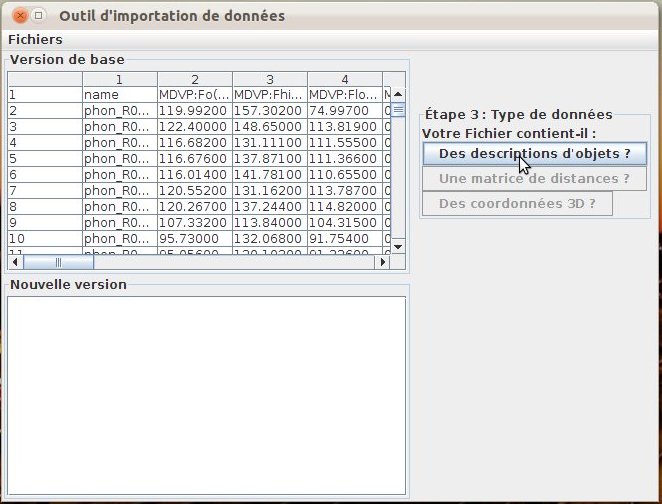
A l’étape suivante, le contenu du fichier est présenté sous forme tabulaire (fig. 40); l’utilisateur indique le type de données importées. A l’heure actuelle, la seule option prise en charge concerne les fichiers attributs/valeurs.
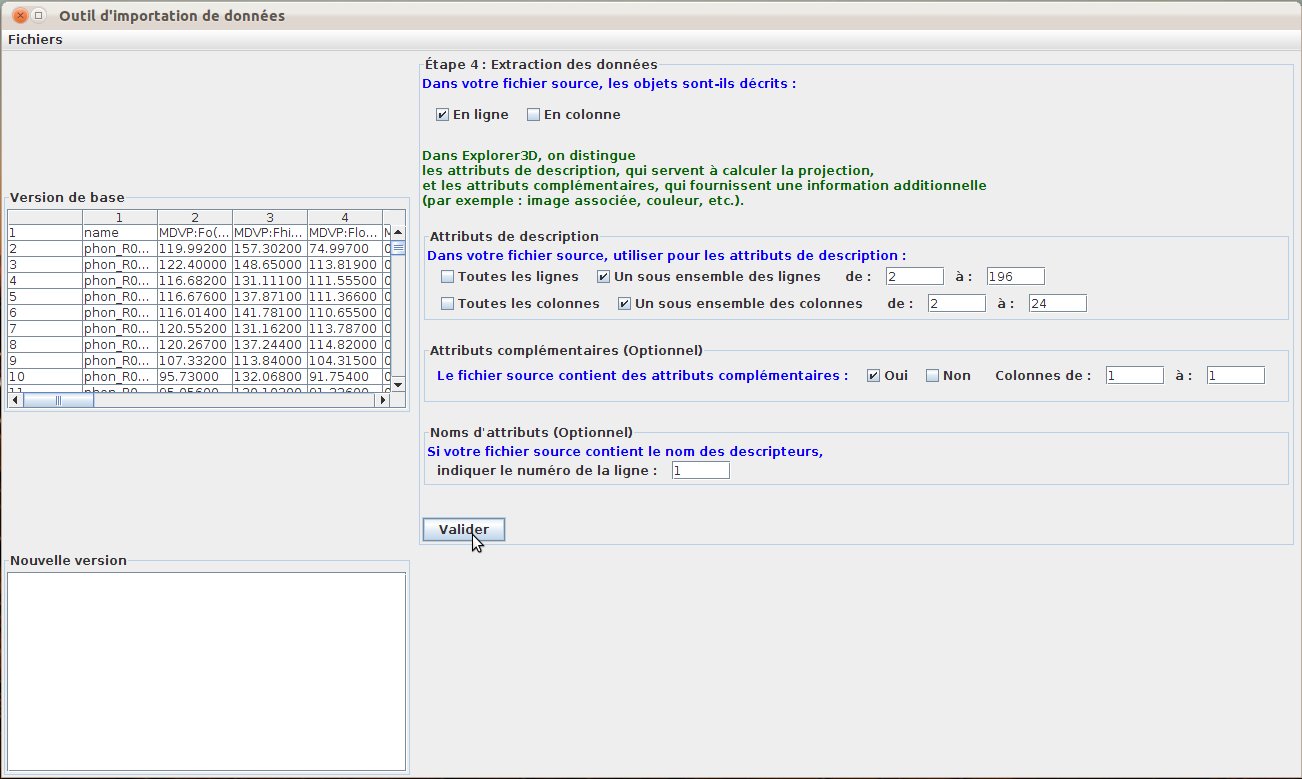
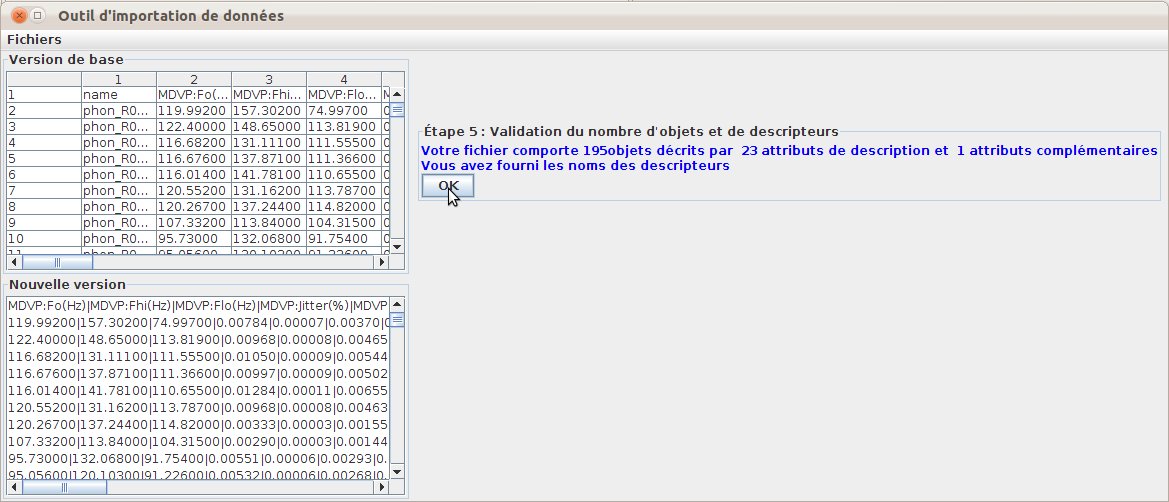
L’utilisateur indique ensuite le rôle des lignes et colonnes dans le fichier source (fig. 41). Dans l’exemple présenté, les objets sont décrit à raison de 1 par ligne. Les attributs descriptifs occupent les lignes 2 à 196 et les colonnes 2 à 24. La première colonne contient les noms des objets; il s’agit donc d’un attribut complémentaire. La première ligne contient les noms des attributs. Dans la version actuelle, les attributs complémentaires et les attributs descriptifs ne peuvent pas être entrelacés.
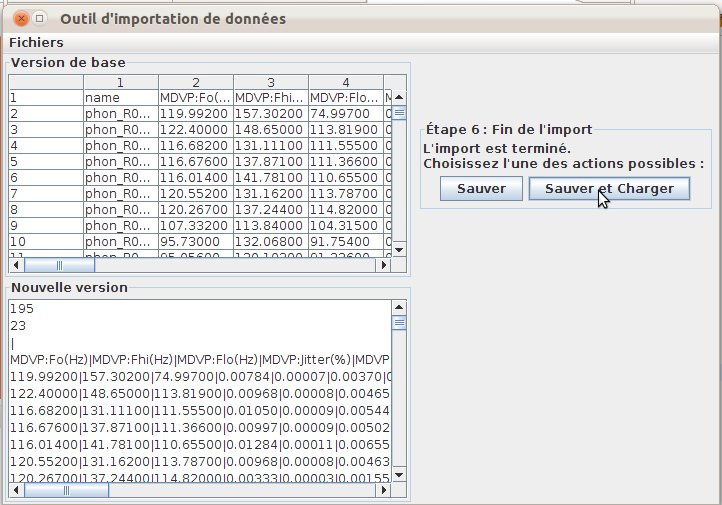
L’outil d’import propose ensuite un récapitulatif des données importées (fig. 42), puis la vue finale du fichier au format Explorer3D (fig. 43). L’utilisateur a le choix entre une sauvegarde pure et une sauvegarde suivi du chargement du fichier. La figure 44 présente l’ACP issue de ce jeu de données après import.