


|
|
|
|
Dans ce schéma, les principales unités d'analyse figurent de haut en bas, des plus simples aux plus complexes. Chacun des "noeuds" du schéma est constitué d'un ensemble de données discrètes. Les "flèches verticales descendantes" symbolisent des règles de composition opérant des traitements combinatoires sur les noeuds. Les "flèches bidirectionnelles horizontales en pointillés" traduisent, elles, des relations d'association qui ne sont pas bi-univoques (ou pas bijectives) entre données. La non univocité de ces flèches reflète les phénomènes d'ambiguïté, présents dans toutes les langues naturelles (sur lesquels nous reviendrons bien sûr par la suite).
Figure 2.1 : hiérarchie des niveaux d'analyse des langues naturelles
|
Dans ce schéma, ici encore très simplificateur (il n'intègre pas, par exemple, la composante orale du langage), les données figurent dans des ovales, tandis que les traitements sont représentés dans des rectangles. Les deux principaux rectangles, intitulés respectivement "analyses" et "synthèses", correspondent aux deux tâches principales accomplies par les locuteurs d'une langue. Le fait de bien les séparer provient de l'observation de patients souffrant de lésions cérébrales qui affectent en particulier une de ces compétences et pas l'autre. Il n'est pas nécessaire pourtant de faire l'hypothèse que chacun des traitements évoqué dans ce schéma soit réalisé par une aire cérébrale spécifique. Il suffit de considérer qu'il met en évidence un enchaînement des fonctions, indépendamment de leur "implantation" dans un substrat biologique concret.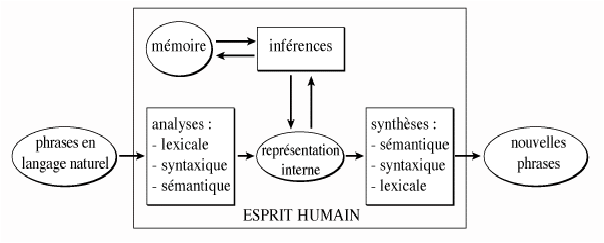
Figure 2.2 : chaîne de traitements classique de compréhension du langage
|