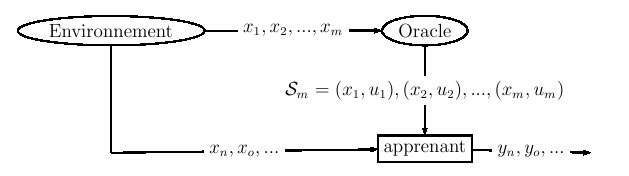
Figure 8.2 : schéma général d'une tâche de fouille de textes
La tâche la plus "naturelle" à envisager, étant donnée la section
précédente, est la
classification de textes. Elle consiste à
ranger des textes ou des documents dans des "classes" prédéfinies :
-
les données sont donc des textes, la plupart du temps
représentés sous la forme de vecteurs. Des variantes de ce type de
représentation ont été étudiées spécialement pour cette tâche, par
exemple pour donner plus d'importance aux mots présents dans des
titres, ou privilégier certaines catégories grammaticales.
- les ressources nécessaires sont celles qui permettent la
représentation du texte : antidictionnaire, lemmatiseur voire
analyseur morphologique, compte d'occurrences, étiqueteur "part of
speech" si on privilégie certaines catégories...
- cette tâche est presqu'exclusivement abordée par apprentissage
automatique, à partir d'exemples de textes déjà classés. Parmi les
méthodes citées en fin de section précédente, celles basées sur des
comptes statistiques ("naive Bayes") ou sur les techniques SVM donnent
les meilleurs résultats.
- il y a de très nombreuses applications concrètes de cette
tâche. L'une d'elle fonctionne déjà sur la plupart des gestionnaires
de courrier électronique : il s'agit du programme qui suggère que
certains des mails reçus sont probablement des "spams" non
désirés. Les deux classes sont alors "spam" et "non spam" et
l'ensemble des courriers déjà reçus constitue l'échantillon
d'apprentissage à partir duquel le programme apprend à poser son
diagnostic. De manière générale, la classification automatique de
textes par "thème" peut rendre de grands services. On peut aussi
utiliser des méthodes similaires pour retrouver l'auteur d'un texte
(l'étiquette de la classe est alors un nom d'auteur) à partir
d'exemples de textes attribués à coup sûr : des critiques
littéraires s'en sont servi pour argumenter que certaines pièces
signées par Molière avaient en fait été écrites par
Corneille. Enfin, l'autre type d'application en plein développement
de la classification est la reconnaissance automatique des opinions
véhiculées par un texte : les classes, dans ce cas sont par exemple
"favorable" et "défavorable". Certaines sociétés qui reçoivent
des courriers électroniques de consommateurs à propos de leurs
produits s'en servent pour analyser leur contenu. Dans ce cas, la
représentation des textes a intérêt à privilégier les adjectifs et
les verbes, qui sont les principaux moyens d'exprimer une opinion.
La
recherche d'information (ou RI) est l'autre "tâche" générale d'ors
et déjà omniprésente dans nos usages quotidiens des ordinateurs. Nous
la sollicitons chaque fois que nous recherchons des documents
répondant à une "requête".
-
la donnée fournie par l'utilisateur est donc une
requête. Celle-ci peut prendre des formes diverses, suivant le
niveau d'expertise de cet utilisateur et la structure de la base de
documents à interroger : simple liste de mots clés, langage de
requête structuré (combinaisons de critères booléens, expressions
rationnelles, requêtes type SQL...), voire document "exemple" dont on
cherche des exemplaires "proches" parmi un ensemble de textes.
- les ressources sollicitées sont tout d'abord le corpus de textes
ou de documents que l'on cherche à interroger. Ce peut être une base
d'articles, une encyclopédie, ce peut être Internet... Comme
précédemment, il est éventuellement fait appel aux ressources
nécessaires à la représentation de la requête par un vecteur. Enfin,
quand la requête est réduite à un ensemble de mots-clés, il est
courant d'utiliser un thesaurus ou une ontologie (chapitre 6, section 1.6) pour l'étendre à
des mots "proches" (par synonymie, ou par généralisation en
"remontant" dans la hiérarchie par exemple).
- on distingue trois familles de méthodes pour aborder la RI :
-
les méthodes booléennes fonctionnent à l'aide d'un
simple index qui donne, pour chaque unité lexicale figurant dans
la requête, la liste des textes où cette unité est présente. Les
requêtes acceptées sont alors généralement des combinaisons de
critères booléens (avec les opérateurs NON, ET, OU). Des calculs
simples permettent d'obtenir la liste des textes où tous ces
critères sont satisfaits en même temps.
- les méthodes vectorielles, comme leur nom l'indique,
codent toutes les informations (la requête et les documents de la
base) sous la forme de vecteurs. La représentation TF-IDF est née
dans ce contexte, et y est particulièrement efficace. La RI se
ramène alors à trouver les vecteurs les plus "proches" d'une
vecteur donné (celui représentant la requête). Pour quantifier ces
distances, on utilise souvent des mesures basées sur le cosinus de
l'angle qu'ils font entre eux (facile à calculer par des formules
mathématiques).
- les méthodes statistiques qui en fait reviennent à
faire de la classification automatique en supposant que l'on
connaît déjà, pour la requête, un ensemble de documents
"pertinents" et de documents "non pertinents", et que l'on
cherche à trouver tous les documents devant être classés comme
pertinents. On le voit, cette méthode n'est pas vraiment
comparables aux autres, puisqu'elle fait des hypothèses
supplémentaires sur ce qui doit être fourni au système. Mais c'est
la seule manière de faire intervenir de l'apprentissage
automatique dans la tâche de recherche d'information.
- la recherche sur Internet est, bien sûr, l'application phare de
cette tâche. Les moteurs de recherche mettent en oeuvre des
méthodes booléennes : leur index fait leur force ! Or ces méthodes
ne permettent pas de classer en "plus ou moins pertinent" les
documents obtenus (en l'occurrence les sites Web). C'est pourquoi
ils doivent employer d'autres techniques (d'où l'importance du
fameux "Page Rank" de Google) pour classer par ordre de pertinence
ces sites. De nombreux autres logiciels existent pour gérer la
documentation d'une société ou d'une organisation : la plupart
fonctionnent par des méthodes vectorielles. Des recherches sont en
cours pour étendre leur domaine d'application aux documents
structurés disponibles sous la forme d'arbres, pour lesquels on veut
autoriser des requêtes mélangeant contenu textuel et structure.
Enfin,
l'extraction d'information est la dernière tâche
fondamentale que nous voulons présenter ici. Comme son nom l'indique,
elle se fixe comme objectif d'
extraire de textes des
informations factuelles précises. Imaginons par exemple les textes de
petites annonces de vente de voitures, rédigées librement. Les
informations qu'elles contiennent peuvent se résumer à la valeur de
quelques "champs" factuels : qui vend quelle type de voiture, de
quel kilométrage, à quel prix, etc. On appelle
wrapper (terme
anglais qui signifie "envelopper") un programme capable de remplir
automatiquement les valeurs de ces champs à partir du texte initial de
la petite annonce. Un wrapper est nécessairement spécialisé dans le
traitement d'un certain type de textes : celui qui traite les petites
annonces de vente de voiture ne saura pas quoi faire d'annonces de
locations d'appartements, et inversement.
-
les données d'entrées sont des représentations de textes de même
type, où la notion de séquence est préservée, elles peuvent
aussi être des documents structurés (pages HTLM ou XML) ; les
sorties sont des données structurées, en général sous la
forme d'une liste d'attributs (prédéfinis) remplie ;
- parmi les informations disponibles au wrapper, on suppose qu'il
y a la liste des champs à extraire (cette liste dépend bien sûr du
type de textes). Les ressources linguistiques utiles à la
réalisation de cette tâche dépendent de la méthode employée : toutes
les techniques d'identification d'entités nommées (liste de valeurs
possibles, mais aussi expressions régulières ou automates) sont
intéressantes car, souvent, la plupart des données à extraire (noms
propres ou valeurs numériques) sont des entités nommées. Des
étiqueteurs grammaticaux, voire des analyseurs syntaxiques, sont
parfois aussi employés.
- pour définir un "wrapper", il est possible de le programmer
directement. Les méthodes les plus efficaces font appel, pour
chaque champ à remplir, à des automates ou à des expressions
régulières qui repèrent les environnements possibles où peut
apparaître l'information visée. Mais, depuis quelques années,
l'apprentissage automatique de wrappers à partir d'exemples de
textes d'où ont été extraits des données factuelles est un thème de
recherche très actif. Certains systèmes ré-exploitent pour cela des
techniques de classification automatique, mais en les adaptant à ce
nouveau contexte. Des compétitions existent pour comparer les
meilleurs programmes.
- Un système d'extraction automatique fournit rapidement un
"résumé structuré" d'un texte. Les données "attributs/valeur"
qu'il fournit en sortie peuvent facilement alimenter une feuille de
calcul ou une base de données relationnelle, ce qui intéresse tous
ceux qui doivent manipuler de nombreux exemplaires de documents
standardisés. Il existe aussi des "wrappers d'arbres"
particulièrement adaptés aux pages HTML, capables d'extraires
certaines des informations contenues dans ces pages, en tenant
compte de leur environnement à la fois textuel et structurel
(balises). Ils sont très utiles aux "veilleurs" chargés de
surveiller les sites qui évoluent beaucoup, afin de les aider à se
focaliser rapidement sur les données qui les intéressent.
| 5 |
Autres tâches plus complexes |
|
La fouille de textes s'attaque à d'autres tâches que nous ne
détaillerons pas. Citons tout de même l'
indexation automatique,
qui consiste à
extraire de textes les termes qui pourront
servir de mots clés attachés à ces textes. Ces termes sont
habituellement repérés par des méthodes statistiques, en cherchant les
mots qui y sont significativement plus présents que dans un corpus
standard de la langue. De même, les méthodes de
résumé
automatique se focalisent, pour la plupart, sur l'
extraction
des phrases caractéristiques d'un texte, sur la base de la fréquence
d'apparitions des mots qu'elles contiennent. Le résumé obtenu n'est
ainsi que la mise bout à bout de phrases statistiquement
représentatives. On le voit, ces tâches font peu appel à des
ressources sophistiquées.
D'autres tâches générales se contentent d'enchaîner les traitements
réalisant des tâches plus élémentaires. C'est le cas des systèmes
"question/réponse". Un tel système peut être vu comme un moteur de
recherche sophistiqué : l'utilisateur lui pose une question en langue
naturelle (par exemple "quand est né Mozart ?"), le système doit
fournir la réponse factuelle à la question (et non un document
contenant cette réponse comme le ferait un moteur classique). Cette
réponse doit être extraite d'un corpus d'informations générales, ou
trouvée sur le Web. Pour atteindre cet objectif, les systèmes
question/réponse procèdent généralement par étapes :
-
la question est tout d'abord envoyée à un système de
classification pour être triée en fonction du type de réponse
qu'elle requiert : ici, une réponse de type
"date-de-naissance". Elle est par ailleurs analysée pour en
extraire les mots clés significatifs : ici, "Mozart" est
évidemment un tel mot clé.
- le ou les mots clés identifié(s) à l'étape précédente servent
ensuite de requête à un système de recherche d'information,
afin de concentrer la recherche sur des documents pertinents (ici :
ceux qui parlent de Mozart).
- enfin, il reste à passer les documents sélectionnés à l'étape
précédente au crible d'une extraction d'information qui se
focalise sur le type de données requis par le type de la
question, tel qu'identifié lors de la première étape.
Chacune de ces étapes fait donc appel à l'un des programmes de la
section précédente. Certains systèmes "question/réponse" font appel
à des ressources un peu plus sophistiquées, comme les analyseurs
syntaxiques (notamment pour analyser la question), mais aucun ne
cherche à réaliser un analyse syntaxico-sémantique complète de
l'ensemble des données auxquelles il a accès : ce ne serait absolument
pas raisonnable en termes de temps de calculs. Plusieurs
"challenges" internationaux portent sur la comparaison des
performances de ces systèmes.
Pour finir, évoquons très brièvement le cas de la traduction
automatique. C'est une tâche dont l'intérêt applicatif ne fait aucun
doute, mais qui est particulièrement difficile. Nous avons vu dans la
section historique du chapitre
2 qu'elle a été étudiée
très tôt par les pionniers de l'intelligence artificielle. Son cas est
intéressant, parce qu'il résume bien à lui tout seul les alternatives
qui se posent au domaine du traitement des langues.
A une extrémité du spectre, on peut procéder comme cela est synthétisé
de façon humoristique sur la
couverture de ce document : en ne faisant
appel à aucune ressource linguistique si ce n'est un "corpus aligné"
qui met en vis-à-vis des phrases traduites les unes des autres, et en
comptant des co-occurrences de mots. Ce n'est pas très satisfaisant
d'un point de vue linguistique mais ça marche : récemment, Google a
gagné un challenge internationnal de traduction automatique, grâce à
un programme qui procédait de la sorte (un peu plus sophistiqué tout
de même), mais fondé sur un "corpus aligné" gigantesque qui a fait
toute la différence. Le challenge portait sur la traduction de textes
chinois et arabes, et aucun des programmeurs de Google embauché pour y
participer ne parlait ces langues : la "chambre chinoise"
(cf. chapitre
6, section
2.1) a
pourtant parfaitement fonctionné !
A l'autre extrémité, on peut chercher à écrire un programme de
traduction sur le modèle du schéma de la figure
2.2, en passant par toutes les étapes
intermédiaires détaillées au fil de nos chapitres : analyse
syntaxico-sémantique de la phrase initiale, représentation de son sens
par un modèle formel, puis synthèse de sa traduction dans une autre
langue. C'est cette méthode qui était privilégié dans les années
70-80. Elle demande beaucoup de travail, n'est malheureusement pas
applicable à très grande échelle et, comme aucun des traitements auxquels
elle fait appel n'est exempt d'erreurs, donne au bout du compte de
moins bons résultats que les techniques statistiques pourtant moins
"intelligentes".
Toutes les approches intermédiaires sont possibles. Un minimum
d'analyse syntaxique contribue à améliorer significativement les
méthodes numériques les plus rudimentaires. La traduction automatique
est sans doute le "lieu" privilégié où cette hybridations entre
méthodes symboliques et numériques sera expérimentée avec le plus
d'acuité.
Pour la plupart des ressources et des tâches citées dans ce chapitre,
il existe de nombreux programmes gratuits et sites Web. Voici un
échantillon représentatif de ceux qui sont testables en ligne :