
Figure 7.3 : représentation graphique d'un modèle
Par ce schéma, on mesure bien que les termes linguistiques
s'interprètent comme des
catégories (cf. chapitre
6, section
1.1) et qu'il peut
exister des relations hiérarchiques entre catégories (cf. chapitre
6, section
1.6) : le fait que
"chat" est un cas particulier de "félin" se traduit par une
inclusion entre ensembles. Un modèle décrit donc de manière
abstraite et rigoureuse un "état du monde" où certaines propositions
sont vraies. Il permet aussi d'
évaluer la valeur de vérité
d'une proposition nouvelle. Par exemple, dans le modèle précédent, la
proposition "Minou est un félin" est vraie mais "Minou est un
humain" est fausse.
Il existe de très nombreuses extensions de ce système, finalement bien
rudimentaire pour traduire tout ce que le langage peut signifier. Par
exemple, la situation dans le temps d'une proposition nécessite des
ajustements. Certains auteurs imaginent l'échelle temporelle comme une
règle graduée (un ensemble d'"indices" ordonnés
t1,
t2,
t3,...) : à chaque indice, il faut redéfinir complètement
l'interprétation, c'est-à-dire la valeur de chaque fonction pour
chaque entité. "Marie dort" peut très bien être vrai à un
certain moment
ti, et faux à l'instant d'après
ti+1... En
généralisant ce principe, on en est même venu à envisager un ensemble
potentiellement infini de "mondes possibles" pour pouvoir
interpréter correctement des propositions comme "il est possible que
Marie dorme" (autrement dit : il existe au moins parmi l'ensemble des
"mondes possibles" un monde où "Marie dort" est vrai). Mais
détailler de telles subtilités nous emmènerait trop loin.
Nous reviendrons dans la partie "modélisation informatique" sur les
formalismes logiques à l'origine de la notion de modèle. L'important
ici est ce que nous suggèrent les logiciens :
comprendre une
proposition, cela signifie être capable d'en créer un modèle. Ce
programme est pris très au sérieux par certains psychologues, qui
estiment que les humains construisent des "modèles mentaux" qui les
aident à raisonner. L'idée n'est pas acceptée par tout le monde, mais
elle est séduisante...
| 2 |
Modélisation informatique |
|
La "théorie de modèles" dont nous venons de parler pourrait bien sûr
être considérée comme une "modélisation informatique". Nous verrons
en effet tout de suite qu'elle s'inscrit dans le cadre plus général de
la
logique, ici envisagée comme un
langage formel de
représentation des connaissances. L'autre famille de modèles
évoquée ci-dessous, à base de
graphes, entretient d'ailleurs
aussi avec elle des liens étroits.
| 2.1 |
Les origines de la logique |
|
La logique, en tant que "science du raisonnement juste" remonte à
Aristote et sa mémoire a traversé les siècles : les étudiants du
Moyen-Age apprenaient par coeur les 14 "figures de syllogismes"
identifiées par ce dernier. La plus célèbre de ces figures permet de
déduire, à partir de propositions de la forme "tout A est B" (par
exemple "tout homme est mortel") et "C est A" (par exemple
"Socrate est un homme") qu'on a nécessairement "C est B"
("Socrate est mortel").
Ramener le raisonnement à un "calcul universel" était un rêve que
Leibniz, grand philosophe du XVIIIème siècle, a aussi caressé. Mais
ce n'est qu'au XIXème siècle qu'on a vraiment commencé à
"mathématiser" la capacité de déduction. On doit à Georges Boole
(1815-1864) un progrès significatif en la matière : les opérateurs
"booléens" lui doivent leur nom. Nous évoquons brièvement ici la
"logique propositionnelle" qui est directement issue de ses travaux.
La logique propositionnelle est un langage formel dont les "formules
bien formées" (syntaxiquement correctes) sont bâties à partir d'un
ensemble potentiellement infini de "variables propositionnelles"
qu'on note traditionnellement
p,
q,
r, etc. Chacune de ces
variables peut prendre soit la valeur "faux" (ou 0) soit la valeur
"vraie" (ou 1). Les formules sont construites de la façon suivante
:
-
toute variable propositionnelle constitue en elle-même une
formule bien formée.
- si p est une formule bien formée, alors ¬p (prononcer
"not p") est une formule bien formée.
- si p et q sont des formules bien formées, alors p∨q
(c'est-à-dire "p ou q"), p∧q ("p et q"),
p→ q ("p implique q") sont aussi des formules bien
formées.
Les symboles ¬, ∨, ∧ et
→ sont les
"opérateurs booléens" auxquels nous faisions précédemment allusion.
¬ est un peu à part : il s'applique sur un seul argument, et a
pour effet d'
inverser les valeurs de vérité. Si
p est vrai,
alors ¬
p est faux, et inversement. Les trois autres opérateurs
combinent deux arguments, à la manière des opérateurs mathématiques
usuels (+, -, *, /). Quand plusieurs d'entre eux sont utilisés pour
construire une formule complexe, on doit utiliser des parenthèses
"(" et ")" pour expliciter l'ordre d'application. La manière dont
ils agissent sur les valeurs de vérités des propositions qu'ils
combinent est donnée dans les "tables de vérité" de la figure
7.4
| p |
q |
p∨q |
| 0 |
0 |
0 |
| 0 |
1 |
1 |
| 1 |
0 |
1 |
| 1 |
1 |
1 |
|
| p |
q |
p∧q |
| 0 |
0 |
0 |
| 0 |
1 |
0 |
| 1 |
0 |
0 |
| 1 |
1 |
1 |
|
Figure 7.4 : tables de vérité
Par ailleurs,
p→ q est équivalent à (c'est-à-dire a
exactement les mêmes valeurs de vérité que) ¬
p∨
q. Cela
signifie en particulier que, d'une proposition fausse, on peut déduire
n'importe quoi. Par exemple, la proposition "si la France est une
monarchie alors le pape est une femme" est vraie car si on la
représente par la formule
m → p où
m signifie "la
France est une monarchie" et
p "le pape est une femme", alors
comme
m doit recevoir dans notre monde actuel la valeur de vérité
"fausse", ¬
m est vrai et l'ensemble de la formule ¬
m∨
p est aussi vraie !
En logique propositionnelle, les affectations de variables
propositionnelles tiennent lieu d'"interprétation", et un modèle est
aussi une affectation qui rend une formule vraie. Par exemple, un
modèle possible de la formule (
p∧
q)∨
r est
l'interprétation :
p=0,
q=1 et
r=1. Une formule pour laquelle
toutes les affectations possibles des variables sont des modèles est
appelée une
tautologie. Par exemple :
p∨ ¬
p est une
tautologie. Une formule qu'il est impossible de rendre vraie, comme
p∧ ¬
p est une
contradiction. Une formule pour
laquelle il existe au moins un modèle est
satisfable, une pour
laquelle il existe au moins une affectation de variables qui la rende
fausse est
falsifiable. Une tautologie est un cas particulier
de formule satisfiable, une contradiction un cas particulier de
formule falsifiable. Une formule qui n'est ni l'une ni l'autre comme
(
p∧
q)∨
r est à la fois satisfiable et falsifiable.
Utiliser la logique propositionnelle pour "représenter des
connaissances" est un peu malaisé et grossier, puisqu'un symbole doit
à lui tout seul "représenter" toute une proposition. Par exemple,
pour signifier "une porte est ouverte ou fermée", on peut définir la
variable
o qui signifie "une porte est ouverte". ¬
o
symbolise alors "il est faux qu'une porte est ouverte" -autrement
dit "une porte est fermée"- et la proposition initiale se représente
donc par :
o∨ ¬
o, qui, on vient de le voir, est une
tautologie. Pour "tout homme est mortel", on peut choisir une
variable
h signifiant "être un homme" et une variable
m pour
"être mortel" : la proposition est alors représentée par la formule
h→ m.
Le point fort de la logique propositionnelle n'est pas dans
l'expressivité de ses formules : il est dans sa capacité à
formaliser des raisonnements. Par exemple, une règle de
déduction simple qui y est applicable est connue sous le nom de
"modus ponens" (ou règle de détachement) : elle stipule que si on a
simultanément deux propositions vraies de la forme
p→
q et
p respectivement, alors
q est nécessairement vraie (ce que
l'on vérifie aisément avec les tables de vérité) et on peut donc la
"déduire". C'est le pendant -un peu approximatif tout de même- du
raisonnement aristotélicien : si
h→ m ("chaque homme
est mortel") et
h ("être un homme") sont vrais simultanément,
alors on en déduit que
m ("être mortel") est également vrai.
Tout l'effort des logiciens consiste à définir des règles de ce genre
qui, en ne prenant en compte que la
forme des expressions
manipulées, garantissent que certaines propriétés portant sur leurs
valeurs de vérité soient satisfaites.
| 2.2 |
Logique des prédicats du 1er ordre |
|
En logique propositionnelle, l'"atome" est la proposition,
elle est indécomposable. Il est donc impossible de rendre compte de
points communs entre propositions, comme le fait que les expressions
"Marie dort" et "Minou ne dort pas" utilisent le même prédicat, ou
que "Minou ne dort pas" et "Minou regarde Marie" partagent une
même entité. La logique des prédicats du 1er ordre, inventée par Frege
à la fin du XIXème siècle, remédie à cette "pauvreté expressive" de
la logique propositionnelle, en opérant une distinction fondamentale
entre "termes" et "prédicats", et en définissant une proposition
comme une
combinaison de ces éléments.
Pour définir le langage de la logique des prédicats du 1er ordre
(abrégée par la suite en LPO), on a besoin de disposer d'un stock
potentiellement infini de
constantes, et d'un stock
potentiellement infini de
variables. Ces dernières serviront
non pas à exprimer des propositions, comme précédemment, mais plutôt à
désigner des entités. On suppose en outre pouvoir utiliser à
volonté un ensemble de
prédicats, chaque prédicat ayant sa
propre
arité. Dans sa forme la plus générale, la LPO permet
aussi d'employer des
fonctions qui, à partir d'un certain
nombre d'arguments, donnent comme résultat un terme (une entité), mais
nous laissons volontairement de côté cette possibilité ici, parce
qu'elle est peu utilisée pour traduire des propositions du langage
naturel.
Les formules de la LPO respectent les règles de construction suivantes
:
-
toute variable et toute constante est un terme ;
- si Pn est un prédicat d'arité n et t1, t2,..., tn
sont n termes, alors Pn(t1, t2,..., tn) est une formule bien
formée ;
- si x est une variable et &Phi une formule bien formée, alors
∃x &Phi (qui se lit "il existe au moins un x tel que
&Phi est vraie") et ∀x Φ ("pour tous les x, Φ
est vraie") sont des formules bien formées. Le terme de "1er
ordre" associé à cette logique provient du fait que les
"quantificateurs" ∃ et ∀ sont nécessairement suivis d'une variable et pas, par exemple, d'un prédicat.
- si Φ et Ψ sont des formules bien formées alors ¬ Φ, Φ∨Ψ, Φ∧Ψ et Φ→Ψ sont aussi des formules bien formées où les opérateurs
booléens ont le même sens que précédemment.
Avec ce langage, on peut traduire en formules toutes les propositions
qui ont donné lieu au modèle de la section
1.3.
Les constantes nécessaires sont "Minou" et "Marie", les prédicats
sont ceux introduits dans cette section, et les formules bien formées
correspondantes sont :
-
"Minou est un chat" : chat1(Minou), "Marie est un humain"
: humain1(Marie) ;
- "Marie dort" : dort1(Marie), "Minou ne dort pas" : ¬dort1(Minou) ;
- "Minou regarde Marie" : regarde2(Minou,Marie) ;
- "un chat dort" : ∃ x[chat1(x)∧dort1(x)] ;
- "tous les chats sont des félins" : ∀ x [chat1(x)
→ felin1(x)].
La LPO est donc bien un langage de "représentation des
connaissances". Il permet d'exprimer des faits et des "règles"
("tous les chats sont des félins" est plutôt une règle générale
qu'un fait instancié) de manière rigoureuse. Là où les langues naturelles
autorisent des ambiguïtés, la logique, elle, impose des choix. Par
exemple, la phrase "Jean qui regarde Paul que Marie aime dort" peut
s'interpréter de deux façons différentes, suivant que Marie aime Jean
ou Paul. Suivant le choix fait, on la traduira donc soit pas :
regarde2(
Jean,
Paul)∧
aime2(
Marie,
Jean)∧
dort1(
Jean),
soit par :
regarde2(
Jean,
Paul)∧
aime2(
Marie,
Paul)∧
dort1(
Jean). Une autre ambiguïté classique tient à l'ordre des
quantificateurs
∃ et
∀ quand il sont présents tous
les deux dans une même formule. Ainsi, pour traduire une proposition
comme "chaque étudiant apprend une langue étrangère", on a le choix
entre :
-
∀ x [etudiant1(x) → ∃ y
[langue_etrangere1(y)∧apprend2(x,y)]]
qui signifie que pour
chaque étudiant, il existe une certaine langue étrangère
(éventuellement distincte pour chacun) que cet étudiant apprend ;
- ∃ y [langue_etrangere1(y)∧∀ x [etudiant1(x)
→ apprend2(x,y)]]
qui identifie une certaine langue
étrangère particulière que tous les étudiants apprennent. Ce sens
prédomine si on met la phrase initiale au passif en disant : "une
langue étrangère est apprise par tous les étudiants".
Traduire en LPO une proposition impose donc de la "désambiguiser"
pour exprimer son sens de manière précise. Les formules de la LPO
peuvent être traduites en termes d'ensembles et de fonctions à l'aide
d'une
interprétation. Une interprétation associe une entité du
domaine à chaque constante et à chaque variable du langage, et une
fonction caractéristique (c'est-à-dire un ensemble) à chaque
prédicat. Comme nous l'avons déjà vu, un modèle est une interprétation
qui rend une formule ou un ensemble de formules vraie(s). Comme en
logique propositionnelle, on peut définir les notions suivantes :
-
une tautologie est une formule telle que toute interprétation
est nécessairement un modèle. C'est le cas de : ∀ x [P1(x)∨¬P1(x)] où P1 est un prédicat quelconque d'arité 1.
- une contradiction est une formule qu'aucune interprétation ne
peut rendre vraie, comme ∃ x
[P1(x)∧¬P1(x)].
- une formule est satisfiable s'il existe au moins une
interprétation qui la rend vraie (c'est-à-dire qui en est un
modèle). Les tautologies sont bien sûr satisfiables. Toutes les
formules traduisant nos propositions de la section
1.3 étaient satisfiables, puisqu'on a pu
définir pour elles le modèle de la figure 7.3.
- une formule est falsifiable s'il existe au moins une
interprétation qui la rend fausse (c'est-à-dire qui n'est pas un
modèle). Les contradictions sont falsifiables. Les formules de notre
exemples étaient aussi falsifiables : il est facile d'imaginer une
interprétation dans laquelle chat1(Minou) est faux...
Comme la logique propositionnelle, la LPO permet aussi de rendre
compte de
déductions. Par exemple, il est évident que dans tout
modèle des formules précédentes, "Minou est un félin", c'est-à-dire
felin1(
Minou) est aussi vrai. De même, en LPO, on traduirait "tout
homme est mortel" par
∀ x [
homme1(
x)
→
mortel1(
x)] et "Socrate est un homme" par
homme1(
Socrate). Tout
modèle rendant vraies ces deux formules rend vraie aussi la formule
mortel1(
Socrate). Pour expliciter ce genre de déductions sans avoir
pour autant à contruire "toutes les interprétations possibles", les
logiciens ont identifié des méthodes qui ne se fondent, encore une
fois, que sur la "forme" des expressions logiques. Il existe ainsi une
sorte de "modus ponens généralisé" autorisant à déduire
mortel1(
Socrate) des deux formules précédentes. Le langage de
programmation Prolog (abréviation de "Programmation logique") est
fondé sur la LPO. Les déductions de ce genre y sont automatisées.
Enfin, il existe de nombreuses variantes et extensions de la LPO, qui
s'interprètent à l'aide des modèles "étendus" du type de ceux
évoqués en fin de section
1.3. Elles s'appellent
par exemple "logique temporelle" ou "logique modale". Mais plus on
gagne en expressivité, plus on perd en efficacité de raisonnement.
| 2.3 |
Exemple récapitulatif |
|
Les systèmes syntaxico-sémantiques qui mettent en oeuvre le
principe de compositionnalité rendent totalement explicite la
succession des traitements qui, partant d'une phrase en langue
naturelle, aboutissent à sa représentation sémantique. C'est le cas de
celui de Montague, dont nous nous inspirons ici. Montrons par exemple
comment produire automatiquement les formules logiques qui traduisent
"Marie dort" et "un chat dort" à partir de l'analyse de ces phrases.
Le formalisme syntaxique employé ici est celui des
grammaires
catégorielles, défini par :
-
un vocabulaire fini : S={Marie, dort, chat, un}
- un ensemble B de catégories de base parmi lesquelles
l'axiome S : ici, nous prendrons B={S,T,NC} (T pour "terme", NC pour "nom commun")
- l'ensemble de toutes les catégories possibles est
l'ensemble des fractions orientées construites à partir des
catégories de base à l'aide des "opérateurs" / et \ comme
: T\S, (S/(T\S))/CN...
Une
grammaire catégorielle est alors une association entre mots
et catégories, comme dans le tableau ci-dessous :
| mot |
catégorie |
| Marie |
T |
| dort |
T\S |
| chat |
CN |
| un |
(S/(T\S))/CN |
Les règles syntaxiques se limitent, elles, à
deux schémas
applicables pour toutes catégories
A et
B comme suit :
-
"Forward Application" FA: A/B B→ A
- "Backward Application" BA: B B\A→ A
Ces schémas sont très similaires à des "réductions de fraction"
mathématiques. Dans ce formalisme, une suite de mots est considérée
comme syntaxiquement correcte si on peut lui associer une suite de
catégories qui, en appliquant ces schémas des feuilles vers la racine
de l'arbre,
se réduit à S. Les grammaires catégorielles sont
un exemple typique de formalisme lexicalisé : ce sont les catégories
associées aux mots qui déterminent comment ils pourront se combiner
les uns avec les autres. Elles ont la même expressivité que les
grammaires algébriques (à la chaîne vide
ε près).
"Marie dort" et "un chat dort" font partie du langage de notre
grammaire, comme en attestent les arbres de la figure
7.5 :

Figure 7.5 : arbres d'analyse syntaxique
Pour obtenir la traduction sémantique de ces phrases, il faut
commencer par préciser la sémantique lexicale des mots qui y
figurent. Comme attendu, "Marie" doit être traduite par une
constante logique notée
Marie, "dort" et "chat" par des
prédicats à un argument notés respectivement
chat1 et
dort1. Nous verrons plus loin quelle traduction associer au mot
grammatical "un". Pour mettre en oeuvre le principe de
compositionnalité, il faut construire un "arbre sémantique", en
partant des feuilles et en "remontant" à la racine, de la façon
suivante :
-
l'arbre sémantique est isomorphe à (c'est-à-dire a exactement la
même structure que) l'arbre syntaxique ;
- les feuilles de l'arbre sémantique sont les traductions logiques
des mots situés à la même place qu'elles dans l'arbre syntaxique ;
- si une règle FA est employée à un noeud de l'arbre
syntaxique alors, au même emplacement dans l'arbre sémantique, il
faut appliquer la formule se trouvant dans le fils gauche de ce
noeud comme une fonction opérant sur celle se trouvant dans son
fils droit ;
- si une règle BA est employée à un noeud de l'arbre
syntaxique alors, au même emplacement dans l'arbre sémantique, il
faut appliquer la formule se trouvant dans le fils droit de ce
noeud comme une fonction opérant sur celle se trouvant dans son
fils gauche ;
- la racine de l'arbre sémantique contient alors la formule
exprimant le sens de la phrase initiale.
La figure
7.6 reprend en l'instanciant
sur la phrase "Marie dort" la partie basse du schéma du principe de
compositionnalité de la figure
7.1. La racine
de l'arbre sémantique en bas à droite du schéma, obtenu en appliquant
les règles précédentes, est bien la traduction logique attendue
dort1(
Marie) de la phrase "Marie dort".

Figure 7.6 : le principe de compositionnalité instancié
Pour finir, expliquons brièvement comment obtenir automatiquement la
traduction de la phrase "un chat dort", à savoir
∃ x
[
chat1(
x)∧
dort1(
x)], à partir de son arbre d'analyse
syntaxique, à droite de la figure
7.5. Notons que,
dans cet arbre, nous avons fait le choix d'associer une catégorie
syntaxique complexe au mot "un", de sorte qu'il "attende" sur sa
droite deux arguments : d'abord un de catégorie
NC (un nom commun),
puis un autre de catégorie
T\
S (un verbe intransitif). La
justification de ce choix est sémantique.
En effet, connaissant déjà les traductions de "chat" et de "dort",
ce qu'il manque pour obtenir la formule finale est quelque chose comme
:
∃ x [
P(
x)∧
Q(
x)], où
P pourrait être
remplacé
par
chat1 et
Q par
dort1. C'est exactement une formule de ce
type que Montague propose d'associer à "un". En faisant en sorte
(par un mécanisme que nous ne donnons pas ici) que l'"application"
de cette formule successivement à
chat1 puis à
dort1 entraîne
une
substitution de ses variables
P et
Q par ces prédicats,
on obtient bien la formule souhaitée. Non seulement le principe de
compositionnalité est alors complètement respecté, mais en plus
l'épineux problème de la nature sémantique des mots grammaticaux
reçoit une solution élégante : les mots grammaticaux doivent être
traduits par des formules logiques "grammaticales", c'est-à-dire
écrites à l'aide de quantificateurs et de variables, mais où les
prédicats restent abstraits, prêts à être
substitués par ceux
qui traduisent les mots lexicaux présents dans la phrase.
Le système de Montague est extrêmement séduisant et a fait l'objet de
nombreux travaux, pour l'étendre et l'affiner tant d'un point de vue
syntaxique que sémantique. C'est le système de référence de tous ceux
qui défendent une application stricte du principe de
compositionnalité.
Pour représenter la sémantique d'une proposition sans faire appel à
des formules logiques, certains auteurs préfèrent utiliser des
graphes ou des
schémas. La théorie des
graphes
conceptuels a ainsi été proposée dans les années 80 par John
Sowa. Le sens d'une phrase comme "le petit chat mange une souris" y
est représenté par le graphe de la figure
7.7.

Figure 7.7 : un graphe conceptuel
En fait, on peut traduire tout le formalisme des graphes conceptuels
en formules logiques équivalentes. Mais les graphes ont l'avantage
d'être plus lisibles et facilement interprétables par des humains. De
même, la décomposition en primitives des verbes d'action, évoquée en
section
1.4, a été utilisée par Schank pour
donner une représentation graphique aux propositions complètes. Par
exemple, dans son système, "Pierre dit à Paul que Jean a donné un livre
à Marie" donne lieu au schéma de la figure
7.8.

Figure 7.8 : un graphe "à la Schank"
Dans ce schéma, outre les primitives MTRANS (qui signifie "transfert
d'information") et ATRANS ("transfert de propriété"), on utilise
les étiquettes "a" pour "agent", "o" pour "objet"
et "d-b" pour un couple "donnateur-bénéficiaire". Schank définit
en fait un ensemble de
rôles conceptuels servant à relier entre
elles les entités intervenant dans son schéma.
Les efforts les plus récents pour étendre ce type de représentations
ont porté sur la sémantique des
discours, où les phénomènes de
reprises anaphoriques (c'est-à-dire de référence, dans une
phrase, à des entités introduites dans des phrases précédentes)
obligent à envisager des modèles plus raffinés. La
Théorie des
Représentation du Discours (DRT en anglais) est née précisément
pour répondre à cet objectif. Une DRS (
Discourse Representation
Structure) est une représentation fondée sur la LPO, mais où les
"référents du discours" sont isolés en "en-tête" de la structure
contenant les formules elles-mêmes, et ainsi rendus accessibles à la
suite du discours. La DRS modélisant "Minou regarde Marie. Elle
dort" est donnée dans la figure
7.9.

Figure 7.9 : une DRS très simple
Cette théorie a permis de résoudre certains problèmes délicats laissés
par la LPO. Le plus célèbre d'entre eux était dû aux "donkey
sentences", dont l'exemple prototypique est la phrase "chaque
fermier qui possède un âne le bat". Pour traduire en logique
cette phrase, on peut proposer la formule suivante :
∀ x [
fermier1(
x)∧
∃ y [
ane1(
y)∧
possede2(
x,
y)]
→ battre2(
x,
y)]
Cette formule n'est malheureusement pas correcte parce que la variable
y présente dans l'expression
battre2(
x,
y) n'a en fait aucune
raison d'être la même que celle introduite par le quantificateur
∃, dont la "portée" s'arrête aux frontières du crochet qui
le suit. En DRT, les quantificateurs ne sont plus nécessaires (ils
sont remplacés par des "règles d'accessibilité" entre en-têtes et
sous-structures) et, cette phrase ne pose pas de problème : elle peut
se traduire par la DRS de la figure
7.10.
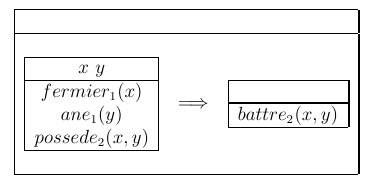
Figure 7.10 : la DRS qui résout les "donkey sentences"
Enfin, la SDRT est une extension récente de la DRT où les liens
rhétoriques entre phrases sont analysés de façon encore plus fine.
Ce tour d'horizon ne doit pas laisser penser que la question du sens
est désormais totalement résolue. Aussi élaborées et séduisantes
soit-elles, les théories abordées brièvement dans ce chapitre sont loin
de faire l'unanmité, et laissent derrière elles de nombreuses zones
d'ombre.
Tout d'abord, le sens commun des mots "et" et "ou" ne coïncide pas
vraiment avec celui des connecteurs logiques correspondants. Ils sont
beaucoup plus ambivalents que ne le laissent penser leur table de
vérité : si "j'aime lire ou aller au cinéma", cela signifie que
j'aime les deux à la fois, mais si on me demande "fromage ou
dessert", je n'ai cette fois pas droit de choisir les deux. Ces
conjonctions peuvent aussi servir à exprimer des rapports de nature
temporelle ou causale ("le verre est tombé par terre et s'est
cassé")...
Les modèles logiques requièrent par ailleurs de représenter par des
"entités" tout ce qui "existe" dans le monde. Mais le mode
d'existence des individus, des mythes (les licornes), des concepts (la
démocratie) n'est pas tout à fait comparable. Est-ce que représenter
le sens du groupe nominal "une bonne idée" par
∃
x[
idee(
x)∧
bonne(
x)] est une si bonne idée que cela ?
Les entités nommées sont aussi beaucoup plus problématiques que nous
ne l'avons laissé croire jusqu'à présent. "Georges W. Bush" désigne
un individu historique précis mais "le président des Etats-Unis"
désigne quelqu'un de différent suivant le temps de
référence. D. Kayser montre qu'un terme comme "Prix Goncourt" est
très polysémique :
-
dans "le Prix Goncourt a été attribué à...", c'est une récompense ;
- dans "X a versé son Prix Goncourt à la Croix Rouge", c'est un montant financier ;
- dans "le Prix Goncourt a été félicité par le Président", c'est une personne ;
- dans "le Prix Goncourt a admis un nouveau membre", c'est un jury collectif ;
- dans "peux-tu m'acheter le Prix Goncourt", c'est un objet (un
livre) ;
- dans "depuis son Prix Goncourt, il est devenu arrogant", c'est un événement ;
- dans "le Prix Goncourt pervertit la vie littéraire", c'est l'existence de cet événement...
Les pluriels et les "quantificateurs généralisés" (comme : "une
partie de(s)", "la plupart de(s)", "beaucoup de(s)"...) sont aussi
difficiles à traduire en formules de la LPO. Et certaines ambiguïtés
les concernant ne peuvent être levées qu'en faisant appel à des
connaissances extérieures : comment expliquer autrement que quand je
vois "trois hommes portant un piano", je ne vois qu'un seul piano,
mais quand je vois "trois hommes portant une barbe", je vois
plusieurs barbes...
Le langage courant, enfin, est truffé de figures de styles qui sont
très mal prises en compte par le genre de sémantique que nous avons
développée ici. Les principales sont :
-
les métonymies, qui autorisent à prendre la partie pour le tout
ou le contenant pour le contenu comme dans "je bois un verre" ou
"je vois une voile à l'horizon" ;
- les métaphores qui transposent certaines propriétés d'une
catégorie à une autre : "l'homme est un loup pour l'homme"...
Nous réalisons sans nous en rendre compte énormément d'inférences lors
de l'interprétation de certaines phrases. Un garçon de café peut dire
sans être ridicule "le sandwich au jambon est parti en courant",
parce que nous avons décodons la métonymie "sandwich"="acheteur de
sandwich" et que nous connaissons les étapes conventionnelles par
lesquelles doit se dérouler la transaction d'un sandwich dans la vie
quotidienne. De même, nous savons bien qu'en disant "le policier leva
la main, la voiture s'arrêta", nous ne parlons pas nécessairement de
Superman arrêtant les voitures par sa force, mais d'un simple agent
qui agit conformément à l'autorité conférée à son costume, et que si
une voiture s'arrête, c'est parce que son conducteur l'a bien
voulu... Lesquelles de ces inférences devraient-elles être modélisées
? Jusqu'où ne pas aller trop loin ?
Schank (toujours lui) a par exemple développé dans les années 70 toute
une théorie pour rendre compte de ce genre de raccourcis. Il l'a mise
en oeuvre dans un système de résumé automatique de dépêches
d'agences de presse, qui essayait d'identifier le domaine dont il
était question avant de remplir des champs prédéfinis. On dit que pour
résumer un article qui titrait "la mort du pape secoue le monde
occidental", le programme avait rempli les champs suivants :
événement="tremblement de terre", victime="le pape"...
De manière générale, la réduction de la sémantique à des formalismes
abstraits a tendance à exclure tout ce qui ne relève pas de la
"fonction référentielle" du langage (cf section historique du
chapitre
2, en particulier les "fonctions du langage"
de Jakobson). C'est aussi la conséquence de notre parti-pris de
ramener le sens propositionnel aux valeurs de vérité. L'ironie ou
l'humour, par exemple, ont besoin d'autres cadres pour être
analysés. Les spécialistes de la pragmatique, c'est-à-dire de l'usage
du langage en situations remettent sérieusement en cause ce
parti-pris.
Le langage courant véhicule une quantité incroyable
d'informations. Toute notre connaissance du monde s'y exprime. Pour le
"modéliser" correctement dans la mémoire d'une machine, il faudrait
d'abord modéliser le monde dans son ensemble, avec ses lois physiques
et son écosystème, sans oublier les conventions sociales et les mondes
imaginaires de ses habitants. Le chantier n'est pas prêt d'être
achevé.
Il existe des programmes capables de transformer des phrases en
représentations abstraites (formules logiques ou graphes), mais ce
sont en général des prototypes au vocabulaire limité. Les sites
suivants sont un peu plus généraux.




