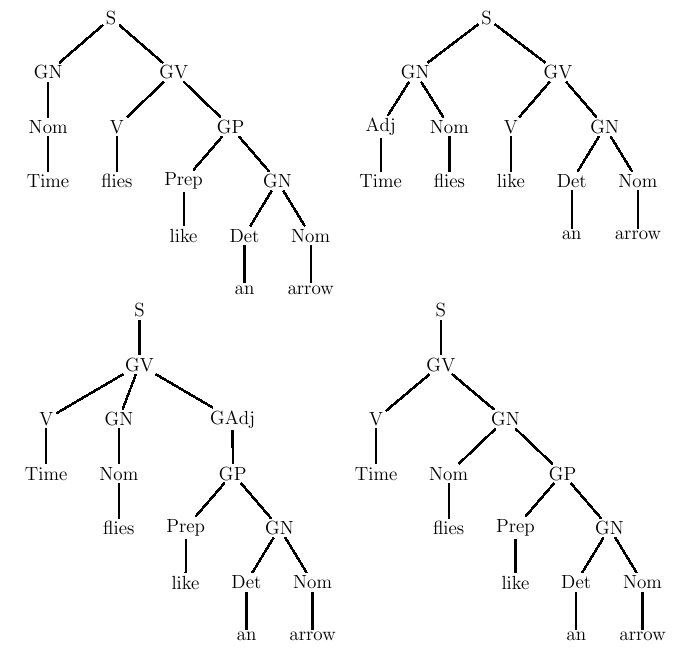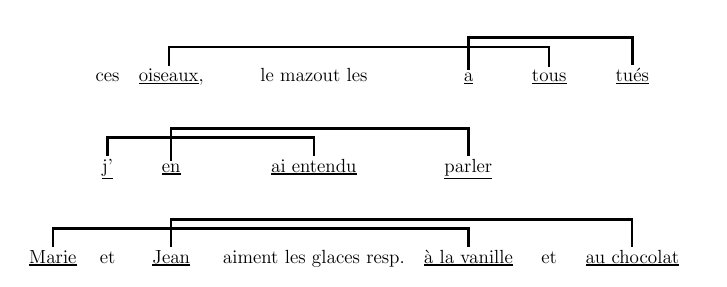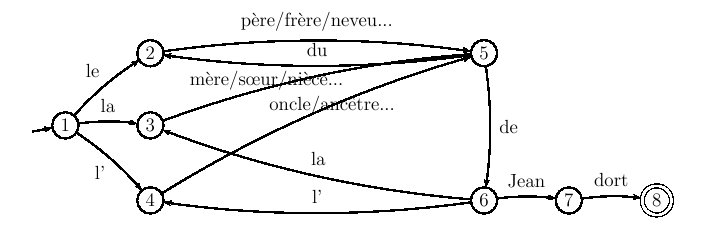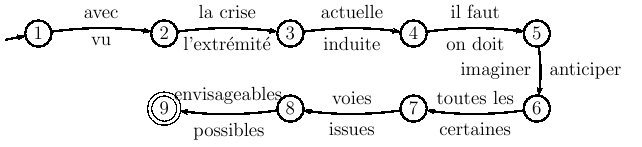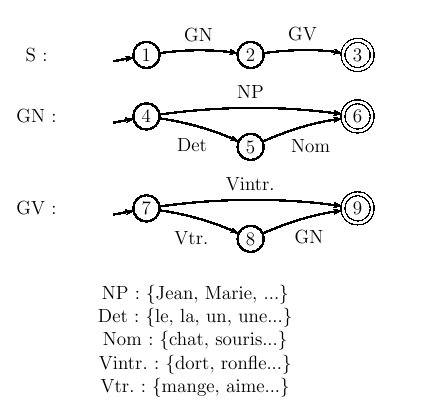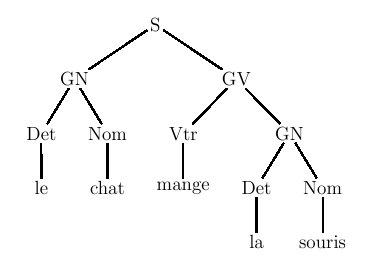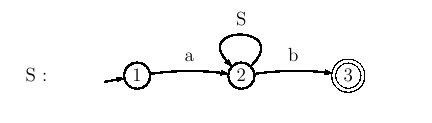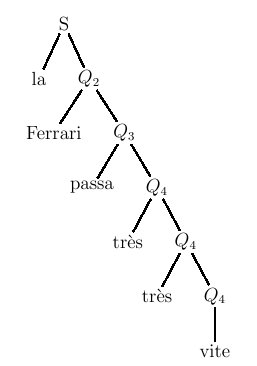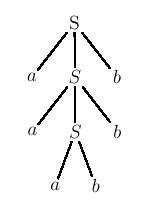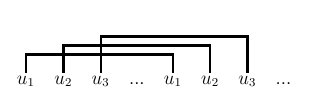
Figure 5.16 : relations croisées dans une phrase de la forme ww où
Or, certains linguistes prétendent avoir reconnu des constructions
relevant d'un des deux langages précédents dans le dialecte suisse
alémanique, ou dans le génitif en géorgien ancien (authentique !), ou
encore dans la manière de compter en chinois... L'argument, qui bien
sûr suppose aussi l'adhésion préalable à la distinction
compétence/performance, est plus difficile à vérifier que celui qui
portait sur les propositions relatives enchassées, mais il est de même
nature.
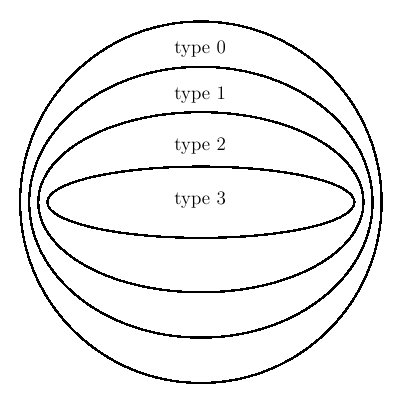
Si on accepte cet argument, est-on pour autant contraint de se rabattre
sur le candidat suivant de notre liste : la classe des grammaires de
type 1 ou contextuels ? Et bien non ! En effet, depuis quelques
années, une classe intermédiaire contenant toutes les grammaires de
type 2 mais strictement plus petite que l'ensemble de celles de type 1
a été identifiée : on l'appelle la classe des grammaires
légèrement sensibles au contexte (traduction anglaise de
"middly context-sensitive"). On ne peut malheureusement pas définir
cette nouvelle classe aussi facilement que les autres, en posant des
contraintes sur la forme des règles. Mais elle présente toutes les
"bonnes propriétés" qu'on pouvait espérer : les grammaires qui en
font partie permettent de produire les langages précédemment évoqués,
et l'analyse syntaxique y est réalisable par des algorithmes
efficaces. Plusieurs formalismes ont été proposés pour caractériser
les grammaires "légèrement sensibles au contexte": le plus célère
d'entre eux est celui des "tree adjoining grammars" ou TAG.
Un certain consensus existe désormais autour de l'idée que la
quasi-totalité des langues naturelles sont "légèrement sensibles au
contexte". Mais le débat n'est pas totalement clos.
On l'a déjà dit : le domaine de la syntaxe est celui qui, depuis 1957
(date de la publication de "Syntactic Structures"), a cristallisé le
plus d'efforts de formalisation. Autant dire que ces quelques pages ne
peuvent qu'en donner une vision très partielle. La présentation qui en
a été faite ici se focalise sur la
théorie des langages, qui
constitue en quelque sorte le socle commun sur lequel peuvent
s'appuyer aussi bien les linguistes que les informaticiens. Elle
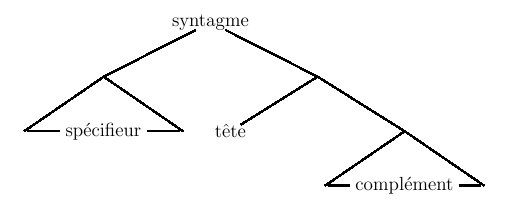
repose sur la notion de
syntagmes, et sur les grammaires
formelles dîtes
syntagmatiques qui les explicitent.
Les langues naturelles ne sont pas toujours faciles à décrire avec ce
formalisme : celles, par exemple, où les relations syntaxiques
s'expriment par des déclinaisons plus que par l'ordre des mots, posent
des problèmes spécifiques. Les accords en genre et en nombre des
langues romanes (comme le français) obligent également à la mise en
place de mécanismes particuliers. Les grammaires formelles décrites
précédemment sont donc en fait très difficilement exploitables telles
quelles en traitement des langues. Mais elles ont donné naissance à
une nombreuse progéniture.
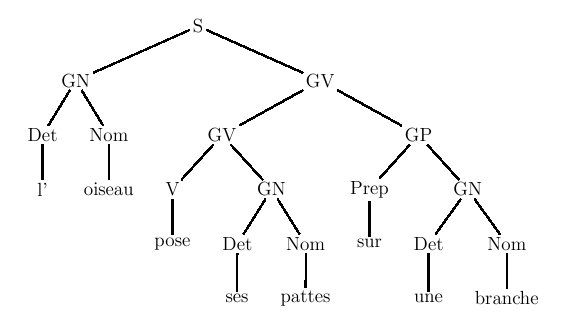
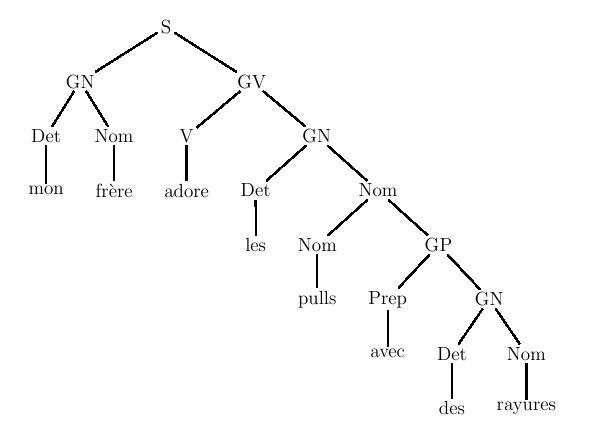
De manière générale, on appelle
grammaire de constituants tout
formalisme qui réalise des analyses syntaxiques sous la forme de
groupes de mots consécutifs récursivement emboîtés les uns dans les
autres. On peut rattacher à cette famille les grammaires LFG, GPSG,
HPSG...
La principale alternative à ce choix est représentée par les
grammaires de dépendances, déjà évoquées en section
1.5. Dans les formalismes de cette famille, les
relations de dépendances entre couples de mots remplacent les
constituants. Il existe aussi, bien sûr, des systèmes hybrides qui,
tout en construisant une analyse de type syntagmatique, marquent
des relations de dépendances.
Les formalismes le plus en usage ces dernières années, quels que
soient par ailleurs leurs partis-pris théoriques, ont un point commun
: ils sont presque tous
lexicalisés. Un formalisme lexicalisé
opère une distinction claire entre les informations syntaxiques
rattachées aux éléments de son vocabulaire (terminal) d'une part, et
les règles qui permettent de combiner entre elles ces informations
d'autre part. L'idéal est de disposer d'un nombre restreint de règles
génériques, communes à toutes les instances de grammaires du
formalisme. Ce qui distingue une grammaire d'une autre se limite alors
aux informations rattachées à chacun de ses mots. Le principal intérêt
de cette distinction est de faciliter les procédures de mises à jour :
puisque les règles sont fixées une fois pour toute, seules les
informations lexicales peuvent éventuellement être modifiées. Les
formalismes lexicalisés les plus connus sont : les grammaires
d'unification, les grammaires catégorielles et les LTAG (variante
lexicalisée des TAG, évoquées en section précédente). Un exemple de
grammaire catégorielle élémentaire est défini et utilisé plus loin, en
chapitre
7, section
2.3.
Enfin, un dernier type de formalisme occupe une place un peu à part
dans ce panorama : celui des grammaires minimalistes, qui essaient de
formaliser les derniers écrits de Chomsky sur la syntaxe. C'est un modèle
lexicalisé, qui ne fait usage que de deux règles génériques :
une règle de "fusion" et une règle de "déplacement". Sa
particularité est de faire l'hypothèse que certaines constructions
syntaxiques sont le résultat de déplacements de constituants qui
laissent derrière eux des "traces". Une trace est en quelque sorte
la "place vide" laissée par un constituant qui a été déplacé : bien
qu'invisible, elle est censée avoir des effets mesurables sur
l'ensemble de la phrase dont elle fait partie.
L'expressivité de ces formalismes est variable : certains ne peuvent
engendrer que les langages appartenant à une certaine classe de la
hiérarchie de Chomsky, d'autres sont plus génériques. L'étude des
propriétés de ces modèles, leurs extensions et leurs comparaisons sont
encore des thème de recherche très actifs à l'heure actuelle.
Pour s'initier aux grammaires formelles, on pourra avec profit
télécharger le petit programme pédagogique "Gram" de Jean Véronis
(uniquement pour Windows) :
www.up.univ-mrs.fr/veronis/logiciels/index.html
Il existe par ailleurs de très nombreux programmes, gratuits ou payants, qui
implémentent une grammaire d'une langue donnée, dans un formalisme
particulier. Aucun n'a pourtant la prétention de modéliser la
compétence complète d'un locuteur de cette langue (tous ont leurs
points faibles). Il existe aussi des "chunk parsers" ou encore des
"shallow parsers", qui réalisent des analyses syntaxiques
partielles, "superficielles", au sens où ils se contentent
d'identifier certains constituants non récursifs, sans aller jusqu'à
poduire une structure complète.
Les sites suivants permettent de produire des analyses syntaxiques en
ligne dans diverses langues, et suivants divers formalismes :
Il nous reste maintenant à aborder le dernier niveau de l'analyse
linguistique : le niveau
sémantique, celui qui traite de la
question du
sens qui peut être associé à une unité ou à une
suite d'unités lexicales. Le principal intérêt d'une langue, c'est en
effet qu'elle est
signifiante : elle permet de véhiculer du
sens. La sémantique est ainsi beaucoup plus qu'un niveau "de plus"
dans la chaîne des traitements linguistiques : c'est tout simplement
sa justification, sa raison d'être. Dans notre schéma inaugural de la
figure
2.1, la sémantique constitue une
"dimension" spécifique de l'analyse du langage, et elle se décline
en deux niveaux distincts : celui de la sémantique lexicale, et celui
de la sémantique propositionnelle. Chacun de ces deux niveaux mérite
attention et étude spécifiques, et sont donc l'objet des deux
chapitres qui suivent.