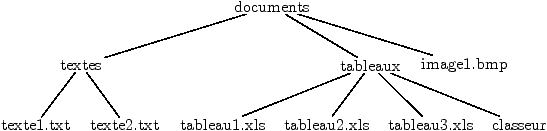
Il convient d'abord de distinguer l'ordinateur lui-même de ses "périphériques", qui ne sont que des constituants annexes. Le coeur d'un ordinateur est constitué :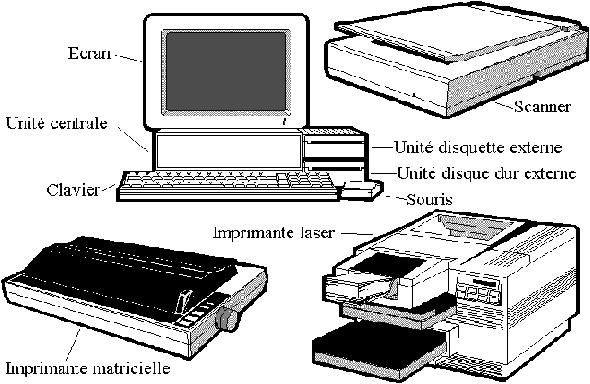
Figure 3.1: environnement matériel des ordinateurs
Les premiers ordinateurs, jusque dans les années 70-80, étaient réduits à une Unité Centrale et des mémoires. Les programmes et les données étaient alors exclusivement fournis sous forme de cartes perforées et les résultats d'un calcul se lisaient aussi sur des cartes perforées...
Figure 3.2: organisation générale d'un ordinateur
Les deux innovations majeures introduites par Von Neumann par rapports aux calculateurs existant à son époque sont, ainsi, l'intégration :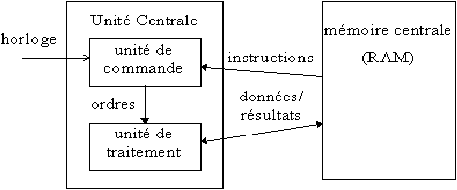
Figure 3.3: architecture de Von Neumann
Une particularité fondamentale de la mémoire centrale, dans l'architecture de Von Neumann, c'est qu'elle sert à stocker indifféremment aussi bien des bits codant des données que des bits codant des traitements, des instructions (on verra par la suite comment coder une instruction dans un mot mémoire). Il n'y a pas de distinction entre les deux, pas de séparation. On retrouve là ce qui caractérisait également les Machines de Turing Universelles, sur le ruban desquelles pouvait figurer aussi bien des données que le code d'une autre machine de Turing (cf. 3.6). Cette capacité à coder avec des 0/1 aussi bien des données que des traitements, c'est le fondement de l'informatique.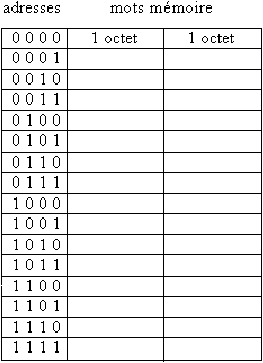
Figure 3.4: structure d'une RAM élémentaire
Détaillons maintenant de quoi est composée une instruction élémentaire, telle qu'elle peut être stockée dans un mot mémoire ou dans le registre d'instruction. Une telle instruction est en fait constituée de 4 parties. Dans notre exemple, chaque partie tiendra donc sur ½ octet soit 4 bits.
Figure 3.5: structure de l'unité de commande

L'UAL est ainsi la "machine à calculer" de l'ordinateur. Elle est simplement constituée de circuits électroniques câblés une fois pour toute pour transformer des 1 en 0 ou des 0 en 1 (c'est-à-dire en fait pour actionner des interrupteurs faisant passer ou non du courant) de façon à ce que les bits du registre résultat correspondent bien au codage du résultat du calcul qui lui est demandé. Elle ne sait faire que des opérations élémentaires (dans notre exemple : simplement les 4 opérations arithmétiques de base).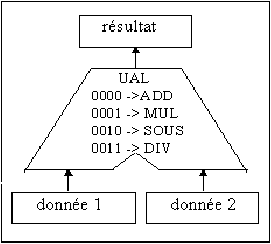
Figure 3.6: structure de l'unité de traitement
Pour aider à la compréhension, on fait à chaque étape figurer en gras les composants actifs à cette étape.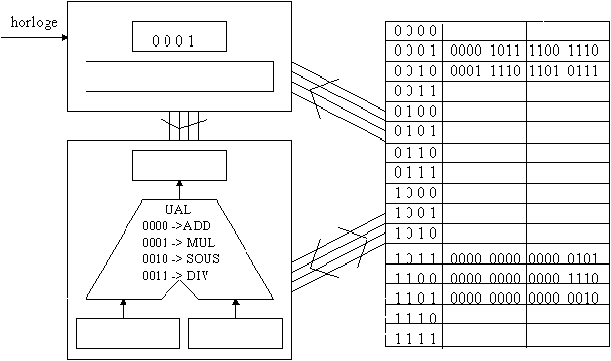
Figure 3.7: situation de départ
La figure 3.9 montre l'état de l'ordinateur à l'issue de la deuxième phase du premier cycle. Le bus "ordres" a fait tout d'abord transiter les 4 premiers bits de l'instruction courante à l'UAL, qui a reconnu que c'était le code d'une addition (l'opération active dans l'UAL est donc l'addition). Les deux suites de 4 bits suivantes correspondent aux adresses en mémoire où l'UAL doit aller chercher les données sur lesquelles effectuer cette opération. Ces données viennent remplir les registres "donnée 1" et "donnée 2" de l'UAL en passant pas le bus "données/résultats".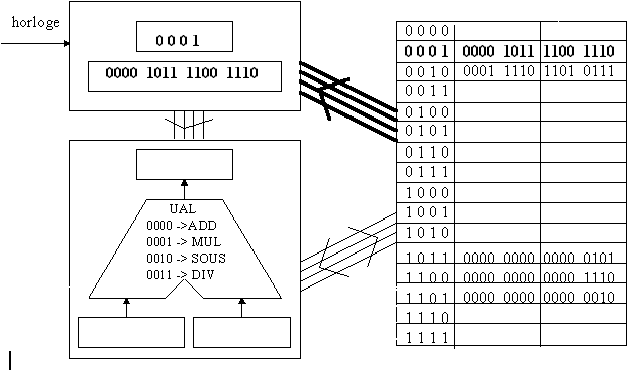
Figure 3.8: premier cycle, phase 1
La figure 3.10 montre l'état de l'ordinateur à l'issue de la troisième et dernière phase du premier cycle. L'UAL a réalisé l'opération qui lui était demandée et a rempli avec le résultat son registre "résultat". La dernière partie de l'instruction courante indique l'adresse du mot mémoire où ce résultat doit être stocké. C'est ce qui est fait en utilisant de nouveau le bus "données/résultats". Par ailleurs, pour préparer le cycle suivant, le compteur ordinal est augmenté de 1.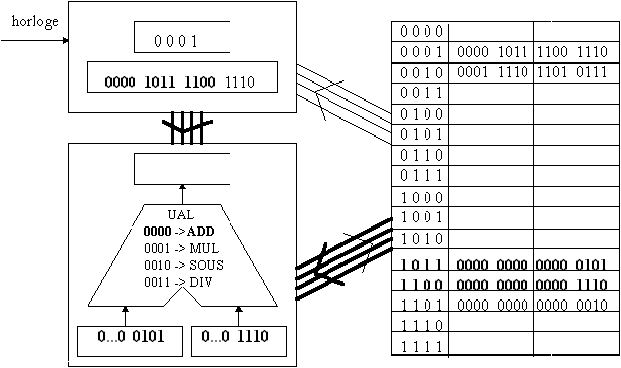
Figure 3.9: premier cycle, phase 2
A l'issue de ce cycle, la première instruction élémentaire a été entièrement exécutée et la machine est prête à démarrer un nouveau cycle pour exécuter la deuxième (et dernière) instruction du programme.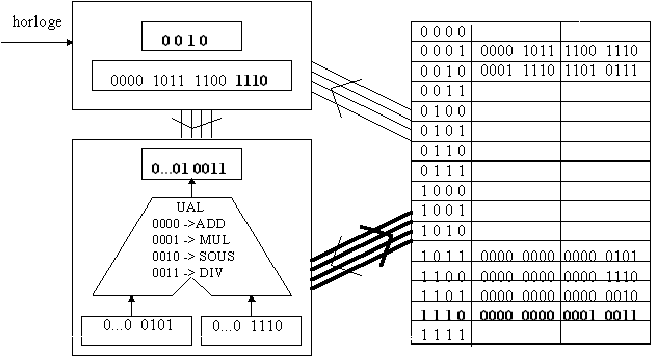
Figure 3.10: premier cycle, phase 3
Mais quel programme, finalement, notre ordinateur a-t-il effectué, sur quelles données, et pour trouver quel résultat ? Reprenons le fil de cet exemple.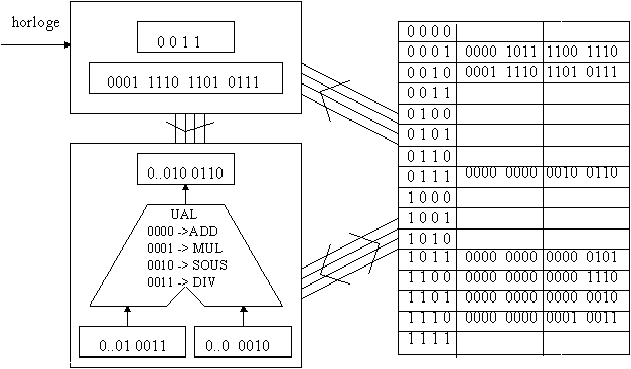
Figure 3.11: situation à l'issue du deuxième cycle
| f : | N3—→N |
| (x,y,z) ⊢→ (x+y)*z |
Dans les ordinateurs actuels les plus performants, ces unités d'échange peuvent elles-mêmes inclure une Unité Centrale spécialisée uniquement dans la gestion d'un certain périphérique ou d'une certaine fonction, constituant ce que l'on appelle par exemple une "carte graphique", une "carte son" ou une "carte réseau".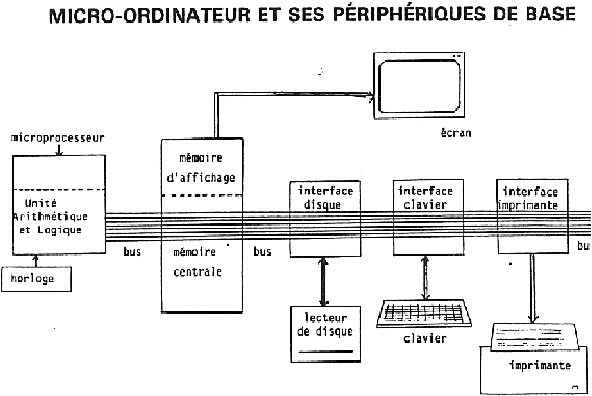
Figure 3.12: relations entre l'UC et les unités d'échange
Les compilateurs étant des programmes, ils sont eux-mêmes écrits dans un certain langage de programmation (et s'ils ne sont pas écrits en Assembleur, ils doivent eux-mêmes être compilés...)..
Figure 3.13: rôle d'un compilateur
Dans ce schéma, les phases d'Analyse et de Traduction sont des opérations intellectuelles humaines, alors que les phases de Compilation et d'Exécution sont réalisées automatiquement par la machine. Le programme source et le programme exécutable sont deux versions numériques (stockées sous forme de bits dans la mémoire) du même algorithme. Le programme source est écrit en langage évolué, alors que le programme exécutable est le résultat de sa compilation. En général, quand on achète un logiciel dans le commerce, c'est uniquement le programme exécutable (illisible, même pour informaticien) qui est fourni. Quand le code source est aussi fourni, on parle de "logiciel libre", puisque tout informaticien peut alors lire le programme (à condition qu'il connaisse le langage dans lequel il est écrit) et le modifier s'il le souhaite.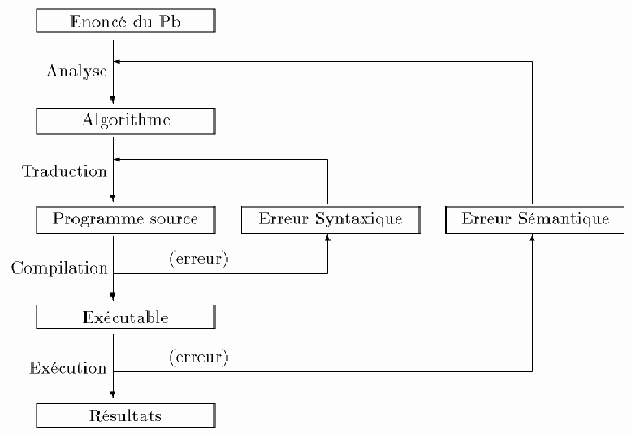
Figure 3.14: démarche de conception d'un programme
Les systèmes d'exploitation les plus couramment installés sur les ordinateurs actuels sont :
Figure 3.15: rôle du système d'exploitation
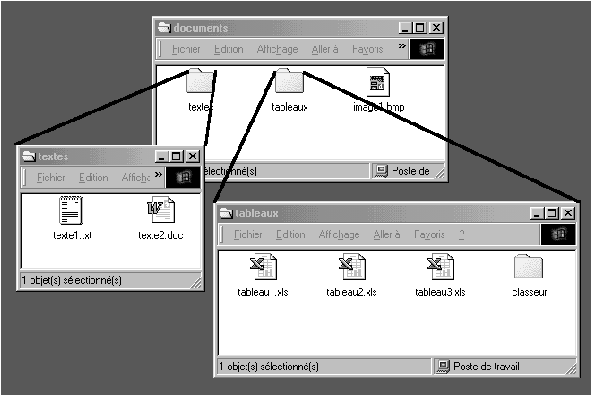
Figure 3.16: copie d'écran d'un environnement Windows
Les couches logicielles peuvent bien sûr se superposer indéfiniment les unes aux autres, comme dans la figure 3.19.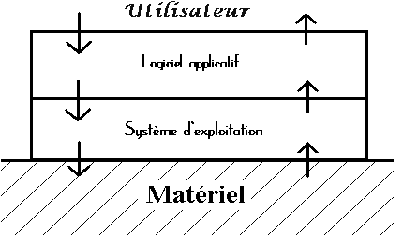
Figure 3.18: emplilement du système d'exploitation et d'un logiciel applicatif
Dans cette dernière figure, Netscape est un navigateur (ancêtre de Mozilla et de Firefox), un "Plug-in" est un logiciel donnant des fonctionnalités supplémentaires aux navigateurs Internet, permettant par exemple de visualiser des vidéos ou d'écouter des fichiers musicaux en MP3.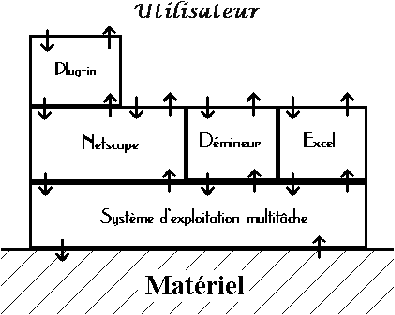
Figure 3.19: emplilement de plusieurs logiciels
Mais une telle solution n'est pas du tout économique en nombre de connexions physiques (il faut mettre des fils partout !) et est de ce fait inapplicable.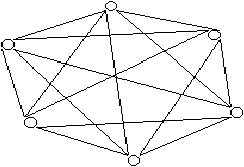
Figure 3.20: réseau à connexion complète
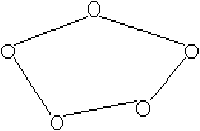
Figure 3.21: réseau en anneau
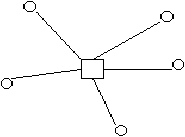
Figure 3.22: réseau en étoile
Pour les réseaux informatiques de petite taille (jusqu'à 100 machines environ), les topologies adoptées sont généralement plutôt en anneau (figure 3.21), en étoile (figure 3.22) ou en bus (figure 3.23). Notons que dans le cas d'un réseau en étoile, le point central auquel sont reliées toutes les machines n'est pas lui-même une machine mais un composant particulier (dans les réseaux informatiques, on l'appelle un "hub").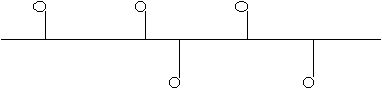
Figure 3.23: réseau en bus
Le plus simple est de l'illustrer sur un exemple. Imaginons donc que dans l'anneau de la figure 3.24, dans lequel la flèche indique le sens de circulation du jeton, la machine A veuille transmettre des données à la machine C. On suppose de plus que le jeton arrive dans l'état "libre" à la machine A. Les étapes de la transmission d'une trame seront alors les suivants :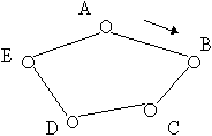
Figure 3.24: exemple de transmission dans un réseau en anneau
Figure 3.25: réseau maillé