Toutes les données citées dans ce tableau (et toutes celles, en général, manipulées par les ordinateurs) ont un point commun : ce sont des données discrètes, c'est-à-dire distinctes les unes des autres et qu'on peut énumérer une par une. Tous les traitements évoqués ici (et tous les autres traitements possibles en informatique) ont également en commun d'être des traitements effectifs, exprimables par des algorithmes. Les fondements de l'informatique sont à chercher dans ces deux notions, que nous allons donc maintenant détailler.
logiciel données traitemements traitement de textes caractères alphanumériques (lettres de l'alphabet, chiffres et tous les autres caractères du clavier) copier, coller, effacer, déplacer, intervertir, changer la casse ou la police, mettre en page... calculs numériques, tableurs, outils de gestion nombres, opérations et symboles mathématiques calculer, écrire et résoudre des équations, faire des graphiques jeux dessins, personnages animés, sons appliquer les règles du jeu bases de données, logiciels documentaires textes, images, données factuelles stocker en mémoire et rechercher des données Internet, CD-Rom toutes les données citées précédemment tous les traitements cités précédemment + communication entre machines, échange de données
Figure 2.1: données et traitements des logiciels courants
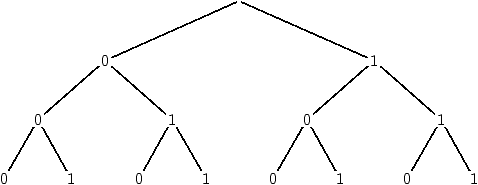
En fait, ajouter un bit multiplie par deux le nombre de combinaisons possibles, puisque le bit ajouté a lui-même deux états possibles. Dans la représentation arborescente, cela revient à dédoubler chaque "feuille" de l'arbre (chaque dernier élément), et donc à multiplier par deux le nombre total de chemins possibles (égal au nombre de feuilles). Ce raisonnement permet de montrer que, avec n bits, on a 2n combinaisons possibles.
Figure 2.2: arbre des combinaisons possibles de 3 bits
Depuis les années 90, une initiative internationale cherche à promouvoir une nouvelle manière de référencer tous les caractères de toutes les langues écrites (actuelles ou ayant existé) du monde : c'est la norme unicode. Elle répertorie environ 250 000 caractères différents, chacun associé à un nombre distinct. Mais cette norme ne fixe pas un codage en bits unique, et peut utiliser un nombre variable de bits (tous les caractères ne sont pas codés avec le même nombre de bits) ; nous ne la détaillerons pas non plus ici.
code ASCII caractère 00100011 # 00100100 $ 00100101 % 01111010 z 01111011 { 00100001 ! 00110001 1
Figure 2.3: quelques exemples de code ASCII
| 103 | 102 | 101 | 100 |
| 5 | 3 | 3 | |
| 2 | 0 | 0 | 1 |
| 25=32 | 24=16 | 23=8 | 22=4 | 21=2 | 20=1 | nombre décimal |
| 1 | 0 | 0 | 1 | 8 + 1 = 9 | ||
| 1 | 1 | 1 | 4 + 2 + 1 = 7 | |||
| 1 | 0 | 1 | 1 | 1 | 16 + 4 + 2 + 1 = 23 | |
| 1 | 0 | 0 | 1 | 0 | 1 | 32 + 4 + 1 = 37 |
| 1 | 1 | 1 | ||||
| 1 | 0 | 1 | 1 | 1 | ||
| + | 1 | 0 | 1 | |||
| 1 | 1 | 1 | 0 | 0 | ||
| 12 | 5 | -3 | 0 | -1 |
| -15 | 7 | 2 | 0 | 5 |
| -8 | -2 | 0 | 1 | 2 |
titre de livre disponible nom auteur prénom auteur date parution Mme Bovary Flaubert Gustave 1857 Notre Dame de Paris Hugo Victor 1831 Les misérables Hugo Victor 1862 ... ... ... ...
Figure 2.4: début d'un catalogue simplifié de bibliothèque
Un son réel est en fait une superposition de courbes de ce genre, mais l'oreille humaine n'est pas sensible à toutes les "harmoniques" qu'il contient. Le principe du fameux format de codage appelé MP3 est, précisément, de ne coder que la partie du son que les sens humains perçoivent.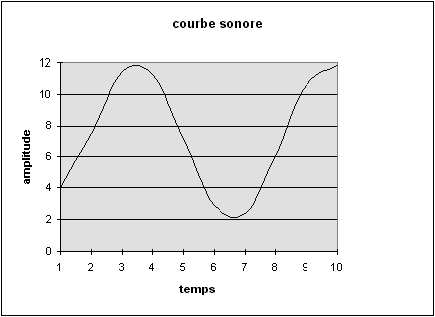
Figure 2.5: courbe sonore continue
Pour coder cette courbe, il suffit maintenant de coder successivement les valeurs correspondant à chaque morceau de temps. Dans notre exemple, ces valeurs successives sont approximativement : 4, 7, 11, 11, 7, 3, 2 6, 11, 12. A condition de connaître la fréquence d'échantillonnage, la donnée de ces nombres suffit à reconstruire la courbe discrétisée, et donc à reconstituer les variations du son initial.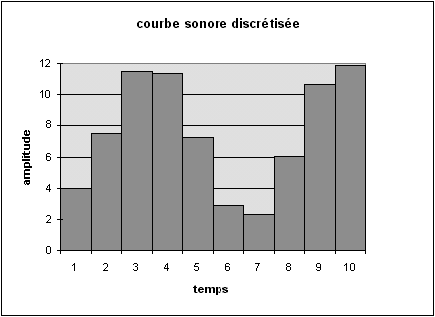
Figure 2.6: courbe sonore discrétisée
Figure 2.7: images bits map
Les coordonnées (supposées entières) des points extrêmes peuvent aussi être codées sur 3 bits. Chaque figure élémentaire est alors représentée par 5 groupes de 3 bits chacun. Par exemple, l'ellipse de la figure 2.8 est codée par : 000 001 100 101 001. Dans ce code, le premier groupe de 3 bit est le code de la figure ellipse, les deux suivants codent les nombres 1 et 4, qui sont les coordonnées (X,Y) du point qui circonscrit cette ellipse en haut à gauche, les deux derniers codent les nombres 5 et 1 qui sont les coordonnées (X,Y) du point qui la circonscrit en bas à droite. Le dessin complet se code par la succession des codes des figures élémentaires (dans un ordre quelconque) qui le composent, soit par exemple :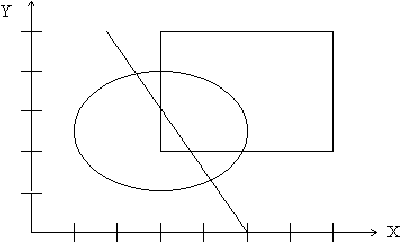
Figure 2.8: dessin vectoriel
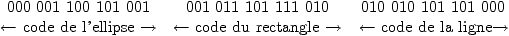
| f : | N—→{0,1} |
| n ⊢→ f(n) |

| f : | N—→ N |
| n ⊢→ n+1 |
| état courant \ symbole lu | 0 | 1 | B |
| 1 | 0,D,1 | 1,D,1 | B,G,2 |
| 2 | 1,D,F | 0,G,2 | 1,D,F |
| 1 | ||||
| 1 | 0 | 1 | ||
| + | 1 | |||
| 1 | 1 | 0 | ||
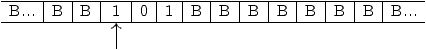

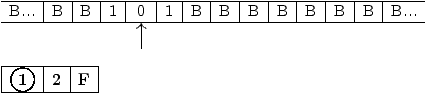
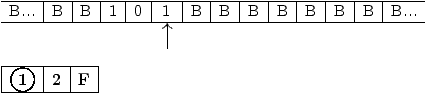
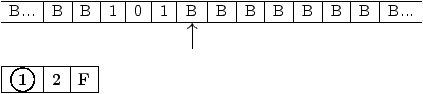
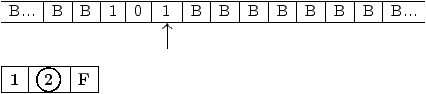
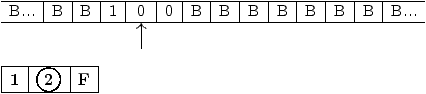
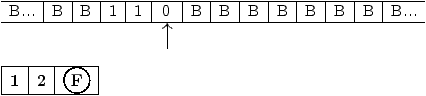
Les états de cette machine ont le sens suivant :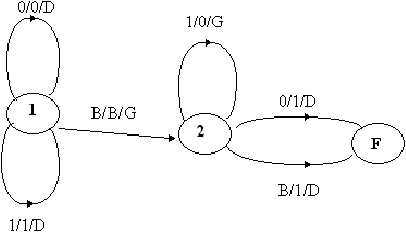
Figure 2.9: graphe de la machine de Turing à ajouter +1